Обновлено 03.08.2022
 Добрый день! Дорогой читатель, я рад что ты вновь посетил один из крупнейших IT блогов рунета Pyatilistnik.org. Не так давно мы разобрали чистую установку Windows Server 2019, научились устанавливать в ней роли и компоненты. Время идет и ваш сервер может накопить большой объем данных, ресурсов на расширение может не быть, а выкручиваться как-то нужно, вот для таких ситуаций есть заумное слово дедупликация. В данном посте мы подробно разберем, что из себя представляет дедупликация данных в Windows Server 2019, что нового там появилось, ну и конечно, как все это настраивается и управляется. Уверен, что данный материал по самой новой серверной платформе будет многим полезен и актуален.
Добрый день! Дорогой читатель, я рад что ты вновь посетил один из крупнейших IT блогов рунета Pyatilistnik.org. Не так давно мы разобрали чистую установку Windows Server 2019, научились устанавливать в ней роли и компоненты. Время идет и ваш сервер может накопить большой объем данных, ресурсов на расширение может не быть, а выкручиваться как-то нужно, вот для таких ситуаций есть заумное слово дедупликация. В данном посте мы подробно разберем, что из себя представляет дедупликация данных в Windows Server 2019, что нового там появилось, ну и конечно, как все это настраивается и управляется. Уверен, что данный материал по самой новой серверной платформе будет многим полезен и актуален.
Что такое дедупликация данных?
Небольшое погружение в текущий цифровой мир. В 21 веке основной вызов перед цифровой экономикой, миром, это огромные объемы информации (Big Data), который генерируется каждую минуту. На одном только Youtube пользователи каждый день заливают сотни тысяч роликов, и на конец 2018 года, только на данном сервисе общий объем занимаемого дискового пространства занимает 11 петтабайт. Прибавьте к этому активно развивающиеся социальные сети, сервисы с просмотром онлайн видео, порно индустрия и многое другое. Компании активно переносят свои сервисы в облачные или виртуальные среды. Из всего этого видно, что объемы данных растут в геометрической прогрессии.
На текущий момент основные производители жестких дисков, технологически не успевают за нуждами людей, сервисов в необходимом объеме дисков и уперлись в жалкие 10-12 ТБ на один HDD.Если рассматривать малый и средний бизнес, то у них в большинстве случаев просто нет возможности в покупке новых серверов или систем хранения данных, которые помогли бы им увеличить объем своих дисковых массивов. Именно борясь с данной проблемой люди придумали концепцию дедупликации.

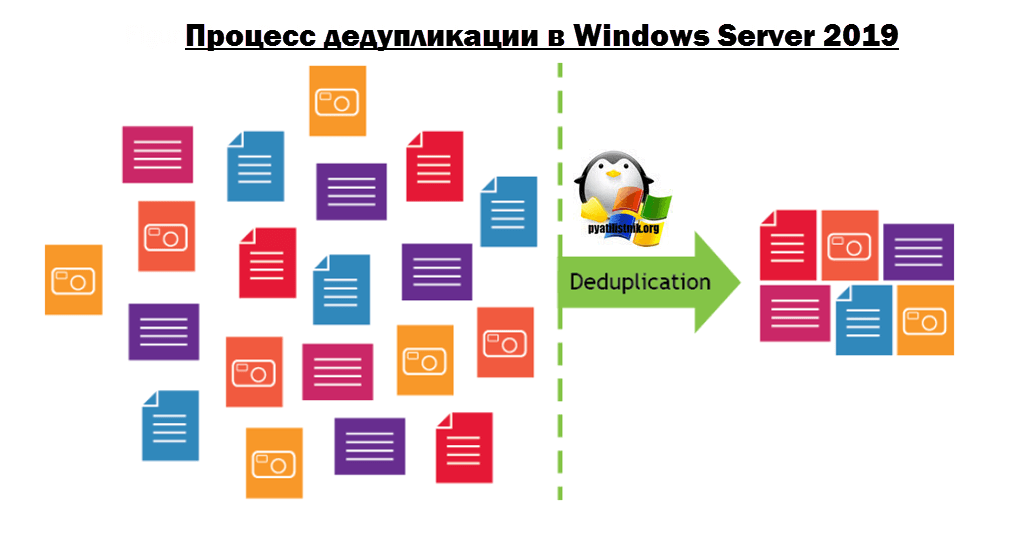
Дедупликация — это метод сокращения потребностей в хранении данных за счет устранения избыточных или дублирующих данных в вашей среде хранения. На носителе хранится только одна, уникальная копия данных, а избыточные или дублированные данные заменяются указателем на уникальную копию данных, если проще, то ссылкой на них.
Таким образом, он просматривает данные на уровне подфайлов (т.е. блоков) и пытается определить, есть ли данные уже. Если это не так, он хранит его. Если он видел его ранее, то он гарантирует, что он сохраняется только один раз, а все другие ссылки на эти дубликаты данных являются просто указателями.
По такому примеру построен дистрибутив всем известной операционной системы Windows 10, где на одном ISO Образе могут быть многие редакции: домашняя, профессиональная, максимальная, у каждой из них по сути одни и те же установочные файлы, а так как это так, то нет смысла хранить на дистрибутиве все эти версии одного и того же, в данном случае имеется только одна копия, и некоторое количество ссылок-указателей на него. Дедупликация делает все то же самое.
Еще очень распространенный пример, это сервис youtube, где есть одно оригинальное видео, которое лежит на дисковом пространстве, все остальные перезалитые ролики, просто ведут на оригинал по ссылке.
Плюсы и минусы дедупликации
Перед тем,как я опишу сам процесс дудупликации, я бы хотел отметить его положительные и отрицательные стороны.
Плюсы:
- Сжатие данных дает малым и средним предприятиям большую выгоду, поскольку они могут увеличить пространство на своих текущих устройствах хранения, удалив дублирующиеся данные.
- Меньшее количество данных может быть скопировано быстрее, что приводит к меньшим окнам резервного копирования, меньшим целевым точкам восстановления (RPO) и меньшим целевым показателям времени восстановления (RTO)
- Дедупликация данных ускоряет процессы резервного копирования, репликации и аварийного восстановления.
- Дедупликация может привести к значительной экономии времени, ресурсов и бюджета. Бюджет всегда стоял краеугольным камнем преткновения для бизнеса. В мелких конторах, где могут быть жадные и ушлые директора, вы лоб расшибете пока будите обосновывать необходимость покупки. Пока не потеряете данные из-за физического отказа железа и бизнесу не будет нанесен простой и урон, вам ничего не купят.
- К плюсам можно отнести тот факт, что данный компонент очень легко и просто устанавливается любым начинающим специалистом.
- Простота переноса данных. Предположим у вас есть сервер с Windows Server 2019, на котором включена функция дедупликации данных. путь на 50%, для примера это 1 ТБ. Вы хотите перенести данные файлы. Это легко можно сделать и в том же дуплицированном виде, если у вас на новом сервере уже будет настроен данный компонент и включен на нужном томе.
- Работает на файловой системе ReFS
- Работает на динамических томах, а так же на томах с BitLocker.
Минусы:
- Существует небольшая вероятность потери данных при дедупликации данных, поскольку система дедупликации хранит данные иначе, чем при их записи. Следовательно, достоверность данных зависит от системы дедупликации. Однако развитие технологий на протяжении многих лет уменьшило вероятность потери данных.
- При использовании встроенного метода дедупликации данные, которые не дедуплицируют хорошо, могут быть стерты, но это актуально в редких случаях на старых версиях ОС.
- Метод дедупликации может быть легко перегружен большими файлами, что может замедлить резервное копирование.
- Некоторые методы дедупликации, такие как постобработка, требуют более сложных конфигураций для правильной работы.
- Она не является заменой резервному копированию
- Не работает с файлами меньше 32 Кб, так же сюда попадают файлы с расширенными атрибутами (extended attributes)
Что нового в дедупликации Windows Server 2019
- Файловая система ReFS обычно используется для виртуализации, резервного копирования и Microsoft Exchange из-за своей отказоустойчивости, оптимизации уровней в реальном времени, более быстрых операций виртуальной машины и большой масштабируемости. Но до недавнего времени ReFS не поддерживала дедупликацию данных, которая была доступна только на томах, отформатированных в NTFS. Дедупликация данных может обеспечить значительную экономию затрат на хранение за счет использования технологии на уровне блоков, чтобы уменьшить объем занимаемых диском файлов.
- Увеличен объем поддерживаемого тома (Volume) до 64 ТБ.
- Максимальное количество томов до 64
- Поддерживаются файлы до 1ТБ
- Процесс дедуплицирования стал доступен с Nano Server редакцией
- Поддержка последовательного обновления кластерной ОС (Cluster OS Rolling Upgrade) — данная функция так же появилась в 2016. Смысл технологии в том, что вы могли обновить ваш Windows Server 2012 R2 до 2019, не останавливая вашего кластера. Там кластер начинал работать в смешанном режиме, это подразумевало нахождение общих данных на узлах кластера с разными версиями компонента дедупликации. Дедупликация в Windows Server 2019 поддерживает этот режим и обеспечивает доступ к дедуплицированным данным в процессе обновления кластера.
- Многопоточность — это наиглавнейшее нововведение, которое появилось еще в Windows Server 2016 и было усовершенствовано в 2019 версии. Лет 5 назад. когда флагманской операционной системой была Windows Server 2012 R2, то в ней процесс дедупликации происходил в один поток, это означало, что он не мог использовать все ядра центрального процессора для одного тома. Согласитесь, что это сильно ограничивало данную технологию и вызывало ограничение на размер тома в 10 ТБ, больше не могла обработать. Выглядит это вот так.
- Внедрена поддержка виртуализированных приложений резервного копирования. В том же 2012, имелся только один вид дедупликации, нацеленный на обычный файловый сервер, технология только развивалась. Представим себе работающую виртуальную машину, логично что ее файлы постоянно используются и открыты, дедупликация не умела с такими работать, тут дело было в неспособности поддерживать службу VSS. В 2012 R2, дедупликация с ней научилась дружить и тем самым работать с открытыми файлами виртуальных машин. В Windows Server 2019 данную технологию расширили и добавили поддержку виртуальных DPM.
- Интеграция с BranchCache
- Возможность исключать необходимые типы файлов от дедупликации, например avi или потоковое видео, так как их сложнее дедуплицировать.
- Поиск битых блоков — данный механизм в очередной раз оптимизировали и улучшили. Один раз в неделю запускается процесс, который ищет мусорные или сбойные блоки, и пытается их исправить. Вы можете его запускать вручную и на более глубоком уровне.
Виды дедупликации
На текущий момент существует три вида дедупликации:
- Файловая дедупликация — тут все просто есть первичные данные, а вторичные заменяются на ссылки ведущие на первые файлы. Данный подход, как я и писал выше применяется в дистрибутиве Microsoft Windows, MS Exchange, SCCM, DPM. Данный вид дедупликации можно назвать S.I.S. (Single Instance Storage). Это самый базовый уровень дедупликации.
- Блочная дедупликация — кто знаком с системами хранения данных, тот знает, что это более низкий уровень работы дисковым пространством. Данный механизм работает на субфайловом уровне, блоков. Тут сам процесс проходит уже не с файлами, а с блоками, я подробнее расскажу об этом чуть ниже. Очень актуально для виртуализованных сред, VDI сценарии. Тут будут обрабатываться блоки от 32 до 128 КБ.
- Битовая дедупликация — это самый продвинутый (Глубокий) тип дедупликации данных, у него самый высокий КПД эффективности. Но тут приходится расплачиваться повышенными затратами на обработку.
Механизм работы дедупликации
Технология дедупликации обычно разделяет данные на более мелкие порции, так называемые блоки и использует алгоритмы для назначения каждому блоку данных уникального хеш-идентификатора, называемого отпечатком. Чтобы создать отпечаток, он использует алгоритм, который вычисляет криптографическое значение хеша из блоков данных, независимо от типа данных. Эти слепки (хэши) хранятся в индексе.
Алгоритм дедупликации сравнивает отпечатки фрагмента данных с теми, которые уже есть в индексе. Если в индексе присутствует отпечаток, блока данных, то блок заменяется указателем на блок данных (ссылкой). Если отпечаток не существует, данные записываются на диск как новый уникальный блок данных.
Более наглядно можно посмотреть на сайте Microsoft (https://docs.microsoft.com/ru-ru/windows-server/storage/data-deduplication/understand)
Эффективность дедупликации
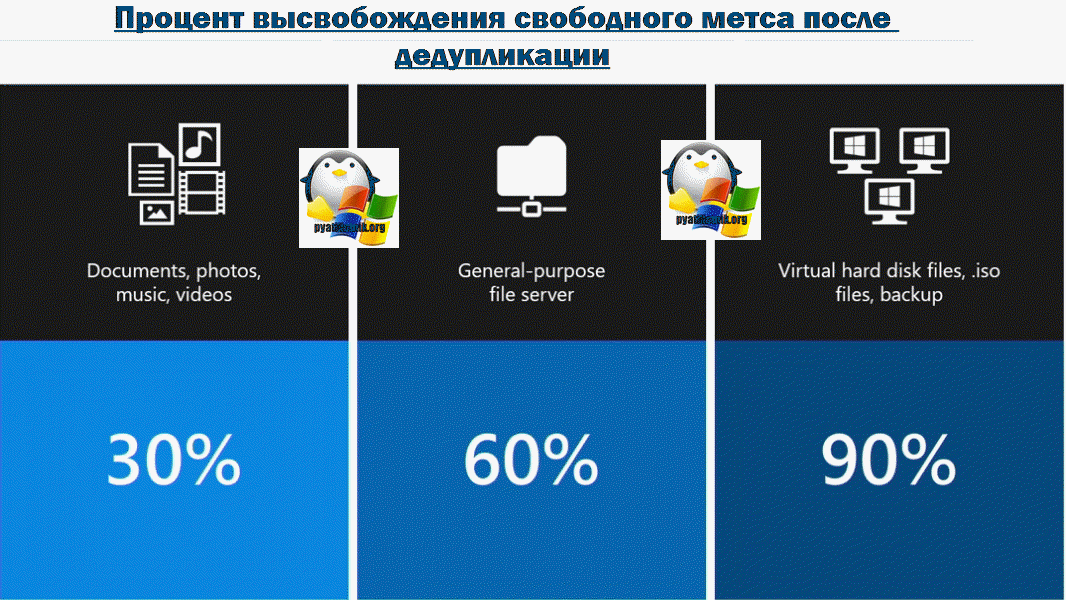
Тут бы я хотел привести среднестатистические цифры, так сказать сколько можно выиграть в попугаях по разным типам данных:
- Видео, музыка, фотографии — тут можно ожидать 30-35% от работы дедупликации данных
- Различные документы и офисные данные — до 60%
- Файлы виртуальных машин в библиотеке шаблонов, например, ISO диски — можно получить до 90%. Для виртуальных сред
Инструменты управления дедупликацией
Существует три инструмента, которые вам помогут отслеживать и управлять процессом дедупликации данных в Windows Server 2019:
- Оснастка «Диспетчер серверов (Server Manager)»
- Командлеты PowerShell
- Веб-инструмент Windows Admin Center
Установка компонента дедупликации через «Диспетчер серверов»
Открываем оснастку «Диспетчер серверов». В правом верхнем углу выберите пункт «правление — Добавить роли и компоненты».
Оставляем пункт «Установка ролей или компонентов» и нажимаем далее.
Далее вы выбираете сервер из пула или же виртуальный жесткий диск.
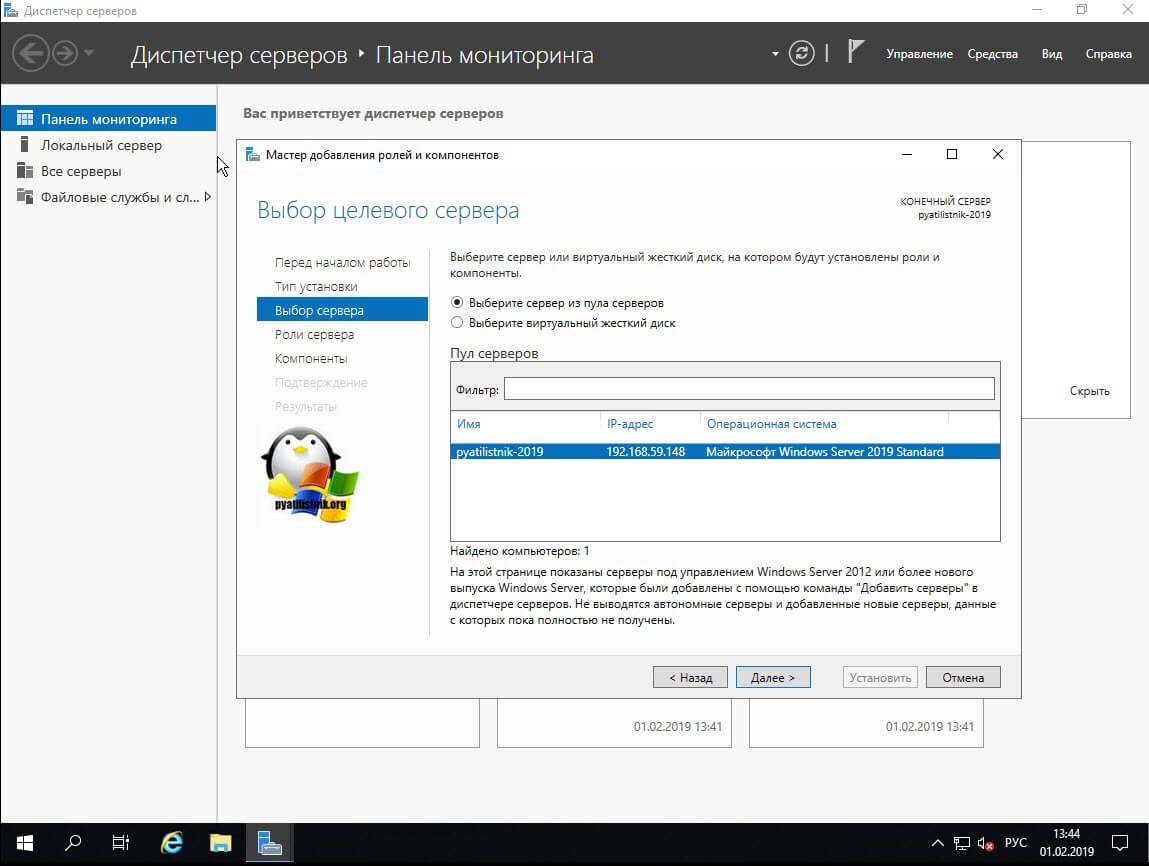
В списке ролей находите пункт «Файловые службы и службы хранилища — Файловые службы и службы iSCSI — Дедупликация данный (Data Deduplication)», ставите на против нее галку и продолжаете установку.
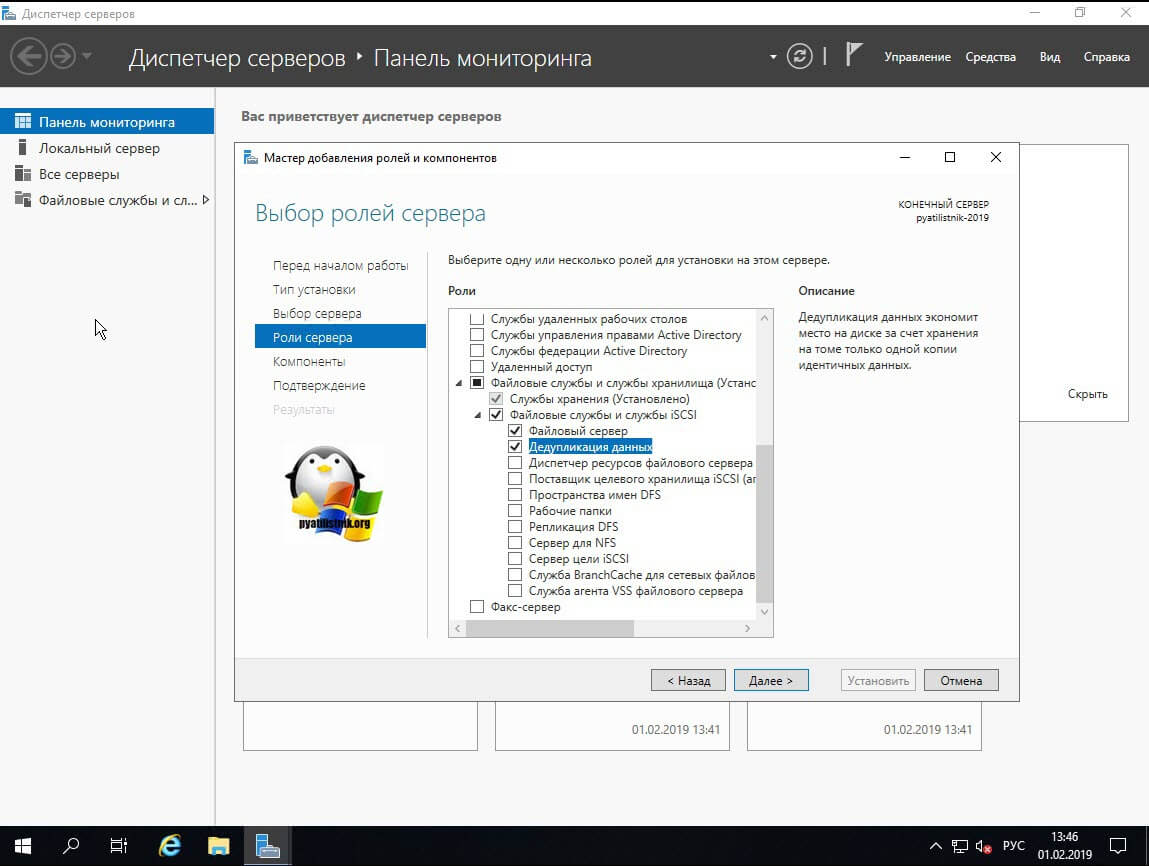
Пропускаем окно с компонентами Windows Server 2019.
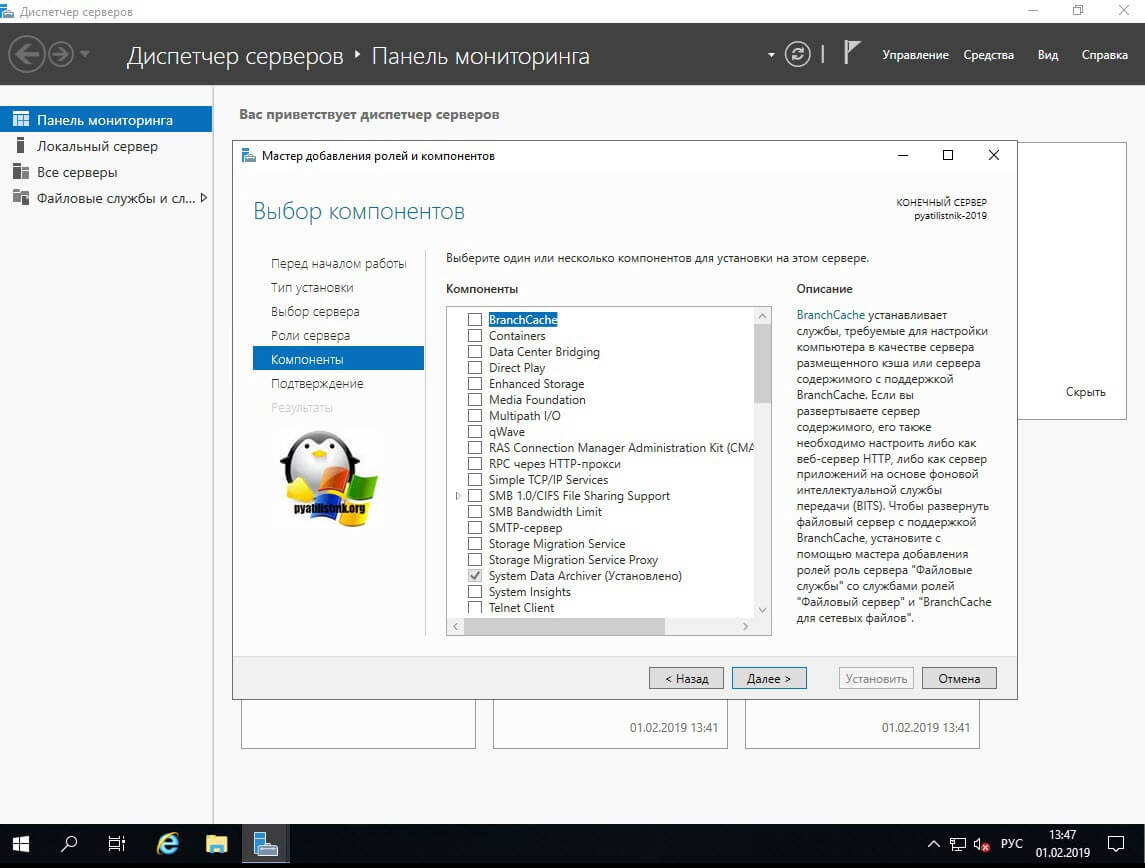
Продолжаем инсталляцию.
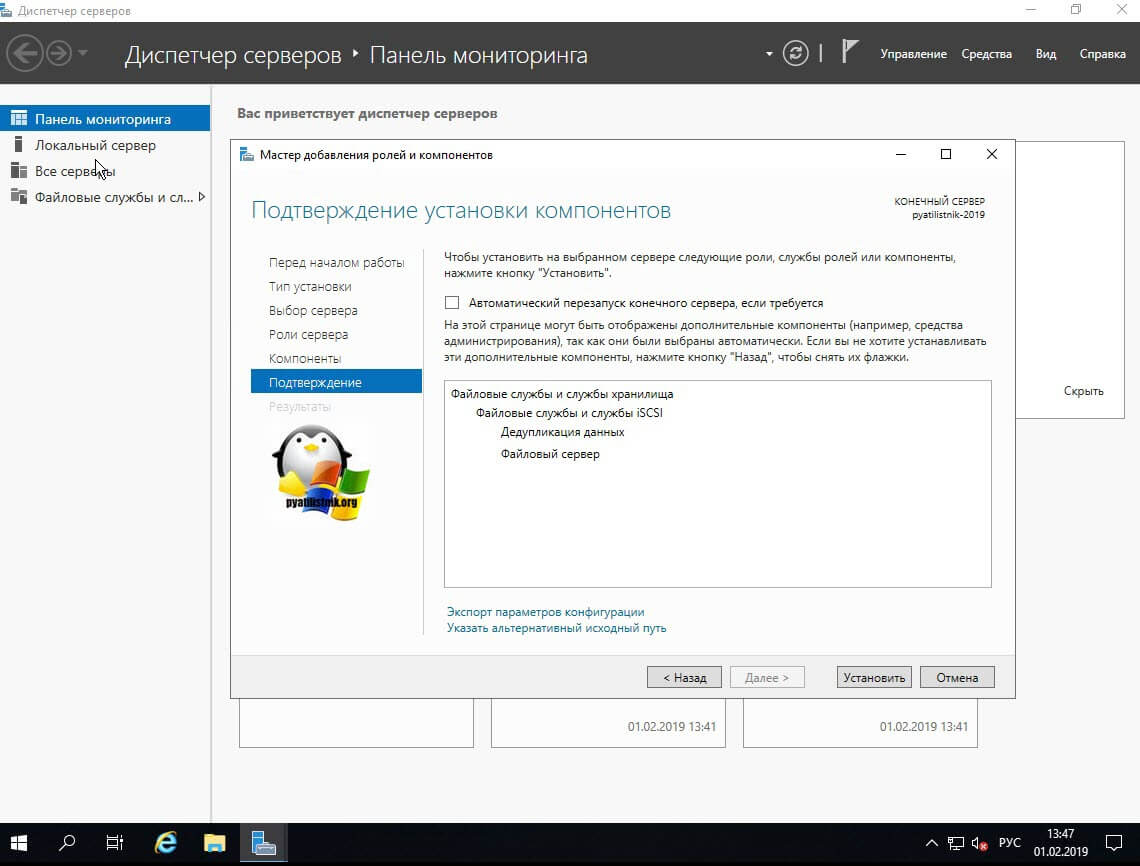
После установки компонента у вас в системе по пути C:Windowssystem32 появится файл ddpeval.exe. ddpeval — это Deduplication Data Evaluation Tool, она позволяет проверить эффективность возможной дедупликации. Что удобно ее можно спокойно копировать на флешку или другие компьютеры и запускать.
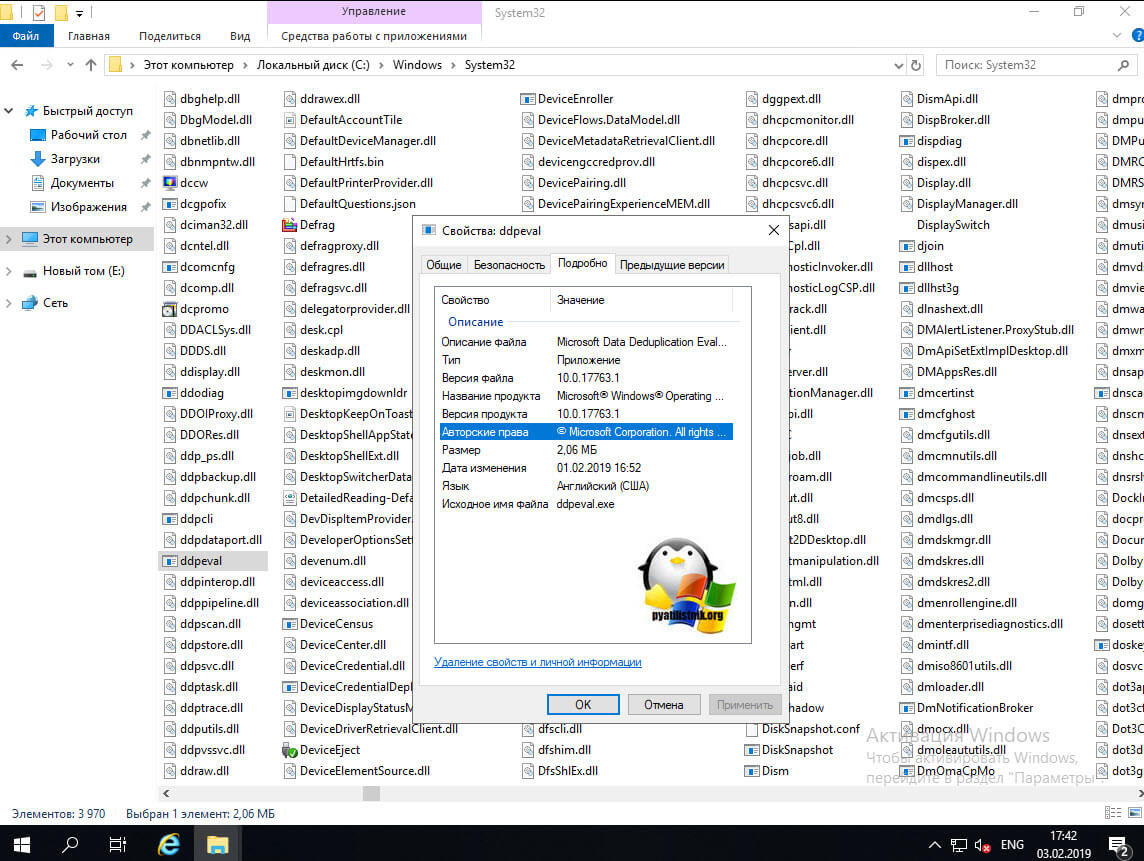
Для примера я запустил утилиту Deduplication Data Evaluation Tool в Windows 10 1809, через командную строку:
Учтите, что утилита ddpeval.exe не работает на системном диске. где установлена система. В моем примере, после того, как программка ddpeval.exe провела сбор данных, я вижу, что их можно оптимизировать за счет дедупликации на 27%, что для SSD-диска, с его не очень большим объемом, отличный результат.
Установка компонента дедупликации через PowerShell
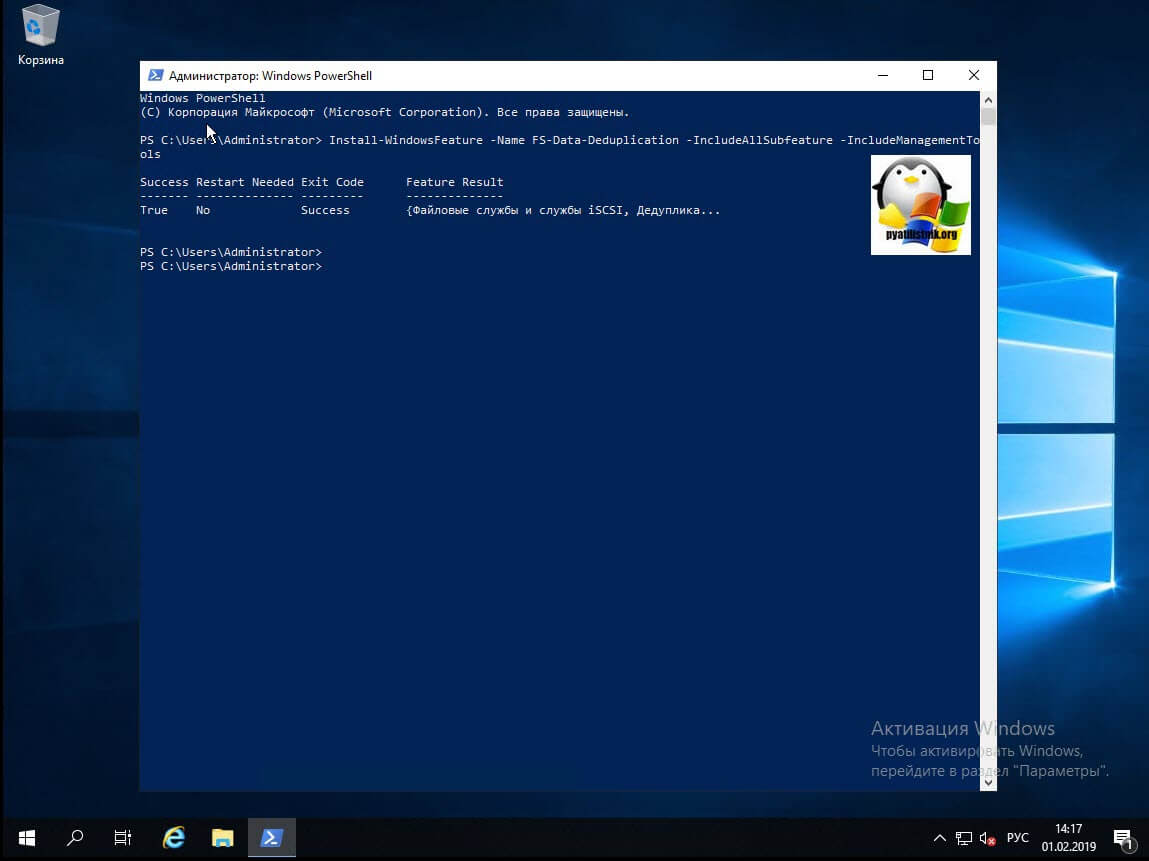
Данный метод куда быстрее, чем графический. Я вам уже подробно рассказывал, о процессе установки ролей и компонентов в Windows Server 2019, тут приведу лишь выдержку из нескольких команд. Открываем оснастку PowerShell и вводим вот такую команду:
Install-WindowsFeature -Name FS-Data-Deduplication -IncludeAllSubfeature -IncludeManagementTools
У вас появится ползунок с процессом инсталляции.
Буквально в течении секунд 20-30 ваш компонент будет присутствовать в вашей Windows Server 2019.
Установка компонента дедупликации через Windows Admin Center
Открываете ваш браузер и подключаетесь к Windows Admin Center. Переходите в пункт «Роли и компоненты», где ставите галку на против дедупликации и нажимаете установить.
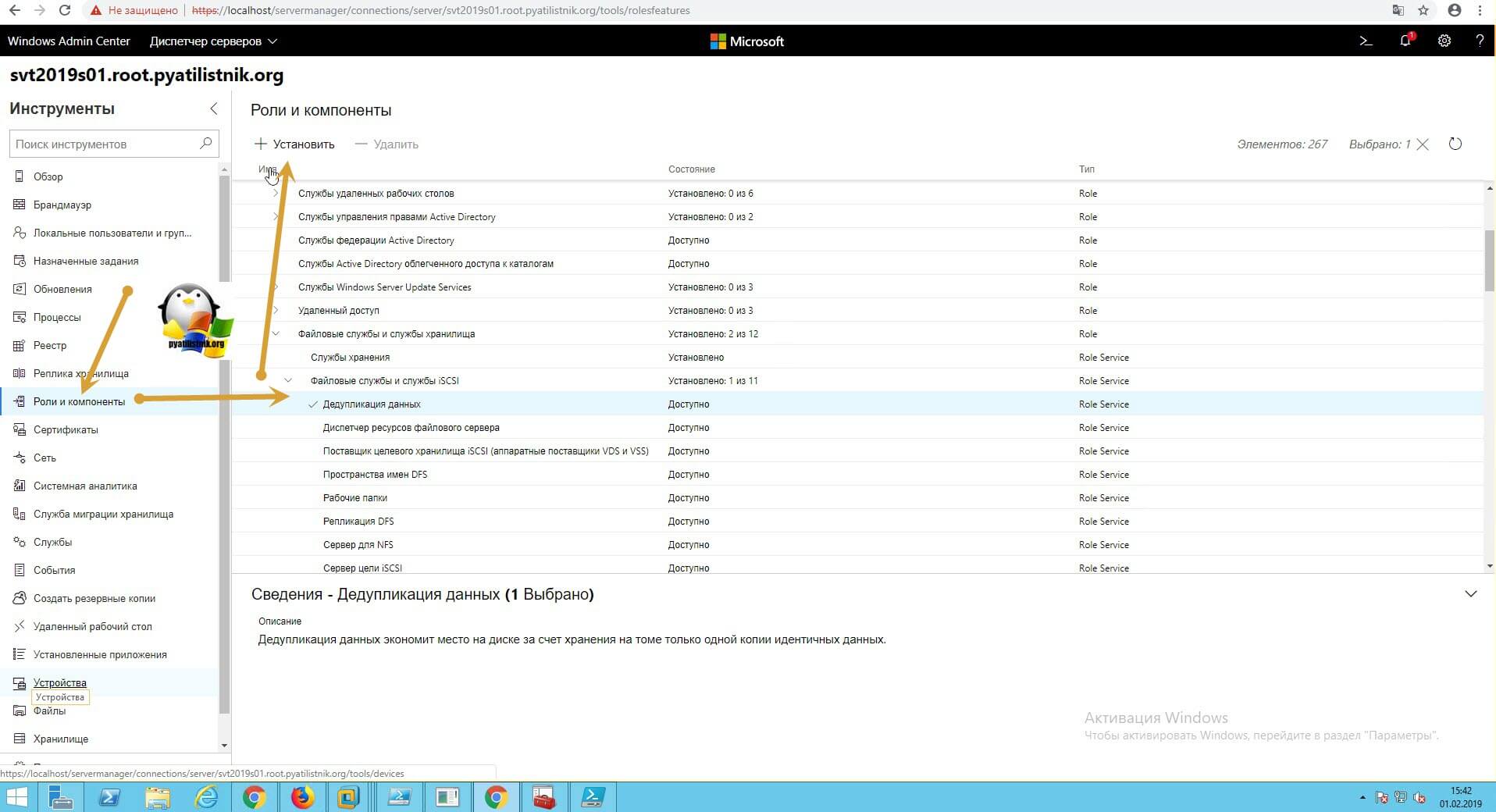
Будет произведен поиск зависимостей, по окончании которого вам нужно нажать»Да».
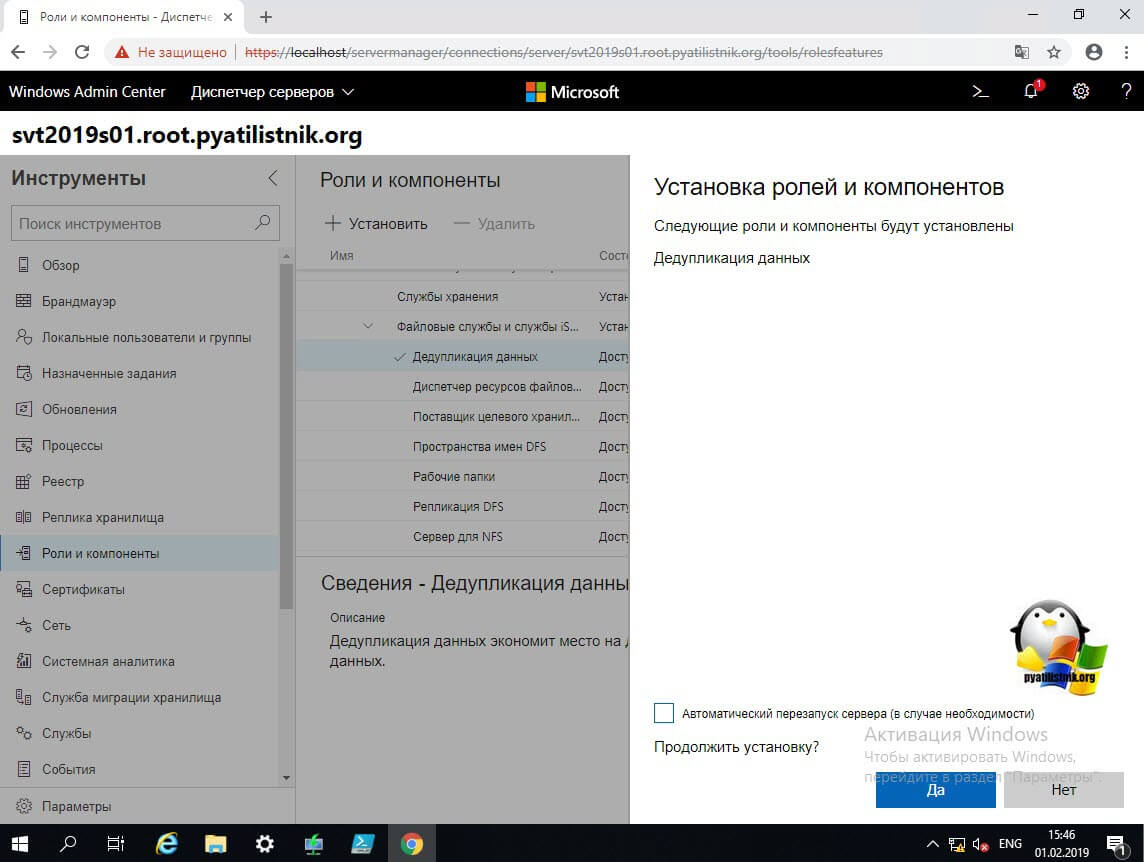
В области уведомления будет отображаться процесс установки.
Включение и настройка дедупликации из GUI интерфейса
И так компонент мы установили, теперь осталось его включить и настроить под свои нужды. Делать мы это будем разными методами, графическими и из командной строки PowerShell. Как я показывал выше через утилиту Deduplication Data Evaluation Tool вы можете оценить степень дедупликации. Если она вас устраивает, то можно ее применять.Еще один момент, перед процедурой я сделал контрольный замер свободного места на диске D.
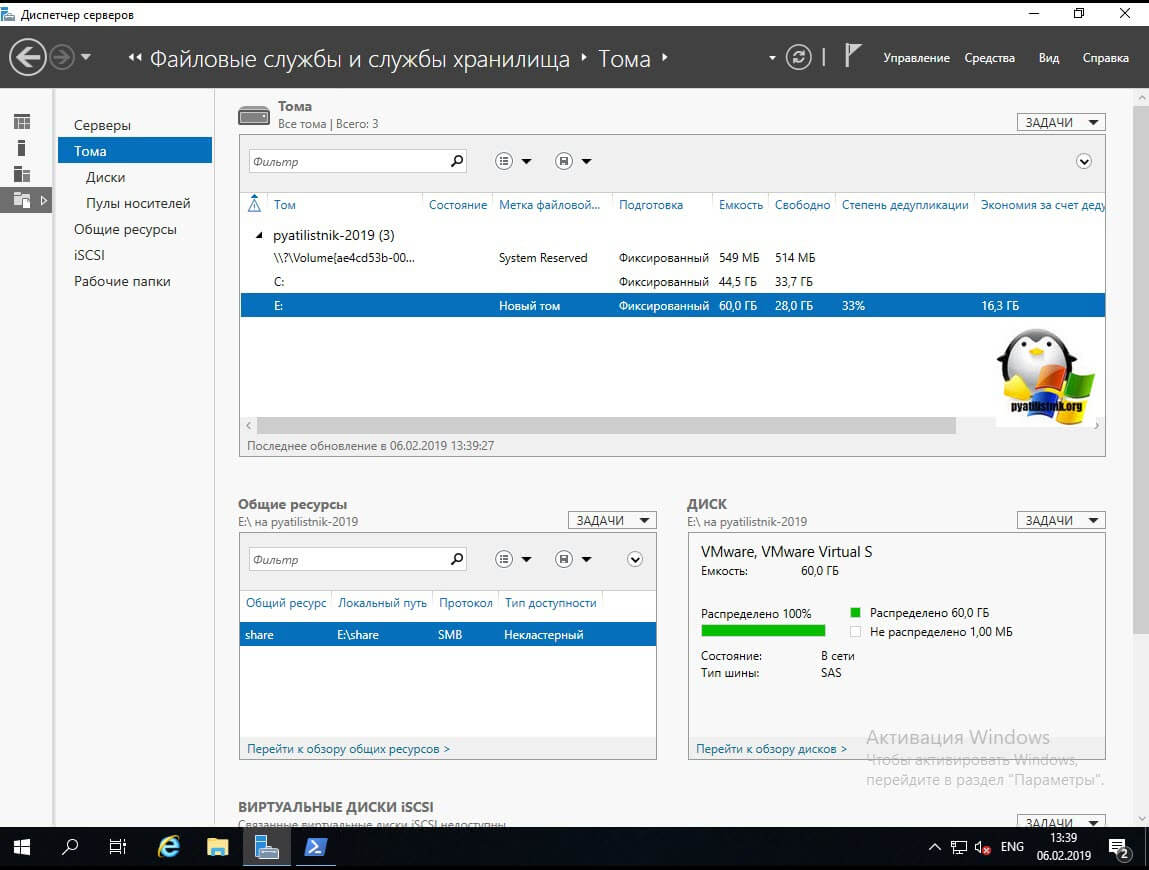
Теперь открываем оснастку «Диспетчер серверов — Файловые службы и службы хранилища».

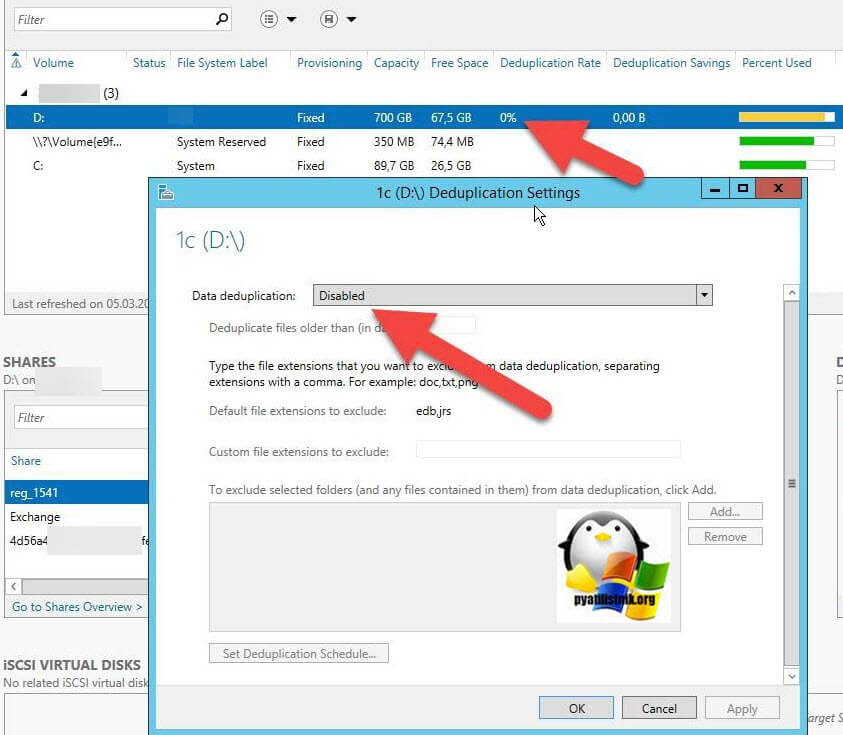
Находим пункт «Тома (Volumes)». Напоминаю, что дедупликация может работать только с ними. У меня в примере есть том с буквой E: именно его я и хочу оптимизировать по распределению дискового пространства. Щелкаем по нему правым кликом и из меню выбираем пункт «Настройка дедупликации данных (Configure Data Deduplication)».
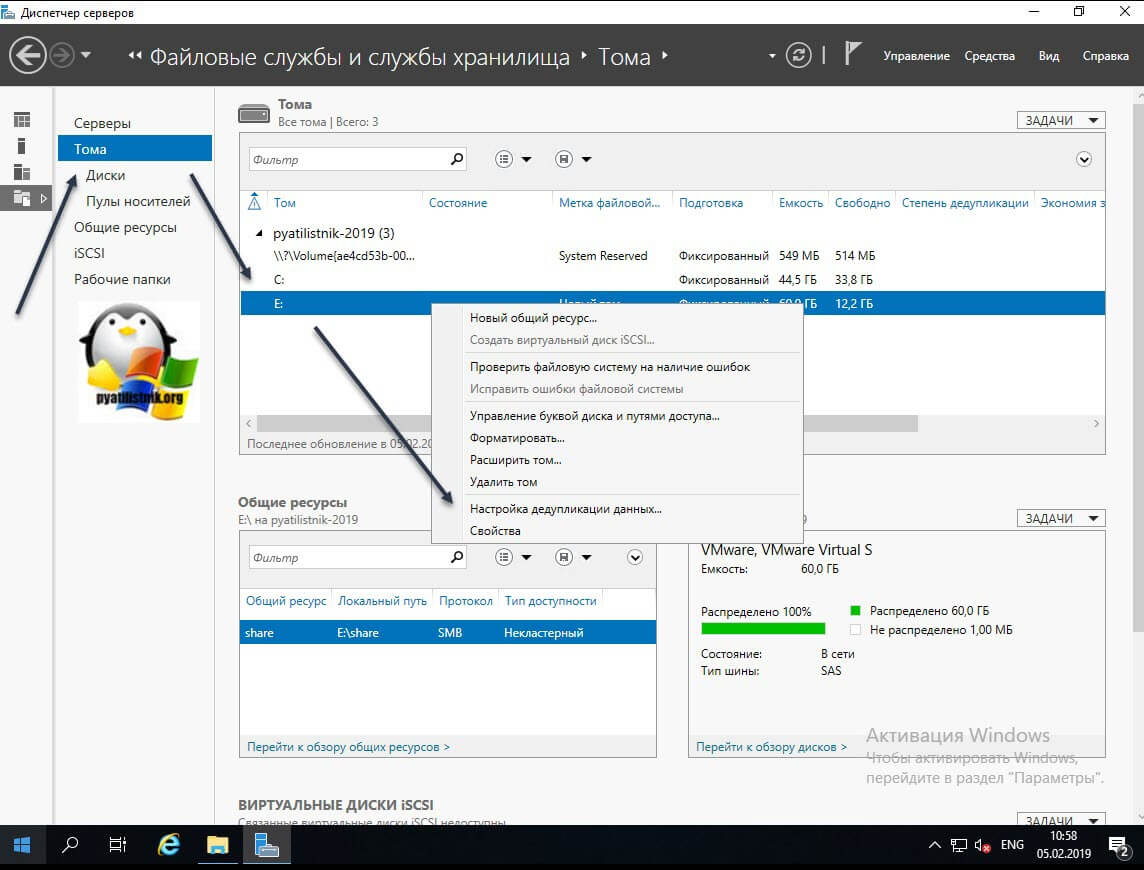
У вас откроется окно «Параметры дедупликации (Deduplication Settings)». По умолчанию дедупликия отключена, в выпадающем окне у вас будет три режима его работы:
- Файловый сервер общего назначения (General puprose file server) — это самый базовый вариант, который используется в подавляющем большинстве случаев.
- Сервер инфраструктуры виртуальных рабочих столов (VDI) (Virtual Desktop infrastructure VDI server), тут думаю понятно из названия.
- Виртуализированный резервный сервер (Virtualized Backup Server), для виртуального DPM
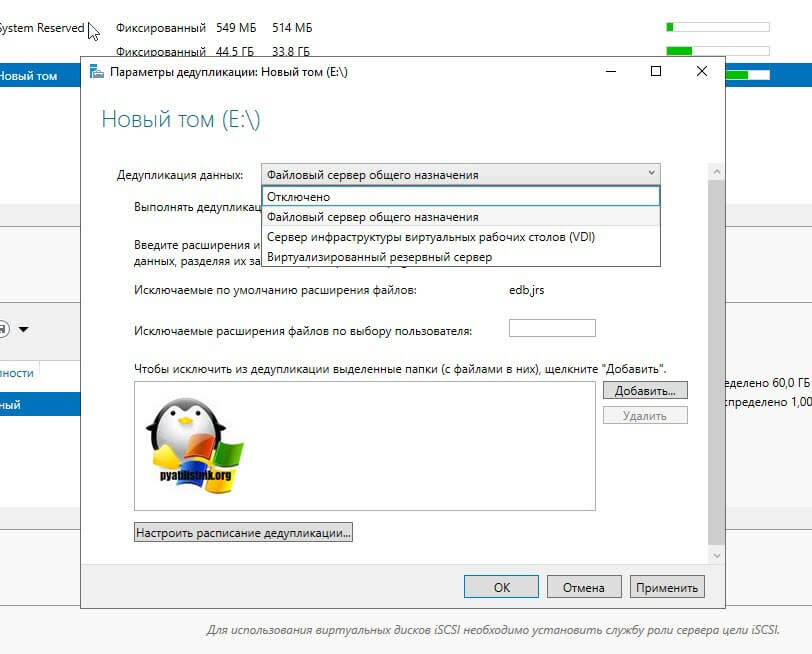
Оставляем выбраным пункт «Файловый сервер общего назначения». Далее вам необходимо определиться с возрастом файлов, которые будут подлежать процессу дедупликации. По умолчанию выставлено значение в 3 дня. Логика в этом есть, это сделано, чтобы отсеять временные файлы, мусорные. Старайтесь не ставить слишком маленькие значения, если у вас очень часто изменяются данные. На практике этого достаточно, но если вам необходимо сделать все сейчас, то установите это значение на единицу.
Далее вы можете определиться с форматами файлов, которые вы не хотели бы дедуплицировать. Тут уже каждый решает для себя сам. Вот вам список самых распространенных форматов файлов, которые вы могли бы исключить.
aac, aif, aiff, asf, asx, au, avi, flac, jpeg, m3u, mid, midi, mov, mp1, mp2, mp3, mp4, mpa, mpe, mpeg, mpeg2, mpeg3, mpg, ogg, qt, qtw, ram, rm, rmi, rmvb, snd, swf, vob, wav, wax, wma, wmv, wvx, accdb, accde, accdr, accdt, docm, docx, dotm, dotx, pptm, potm, potx, ppam, ppsx, pptx, sldx, sldm, thmx, xlsx, xlsm, xltx, xltm, xlsb, xlam, xll, ace, arc, arj, bhx, b2, cab, gz, gzip, hpk, hqx, jar, lha, lzh, lzx, pak, pit, rar, sea, sit, sqz, tgz, uu, uue, z, zip, zoo
Так же есть возможность исключения нужных вам папок из задания. Для примера я исключу у себя папку с TotalCommander. Для этого нажмите кнопку «Добавить» и используя проводник укажите целевую папку.
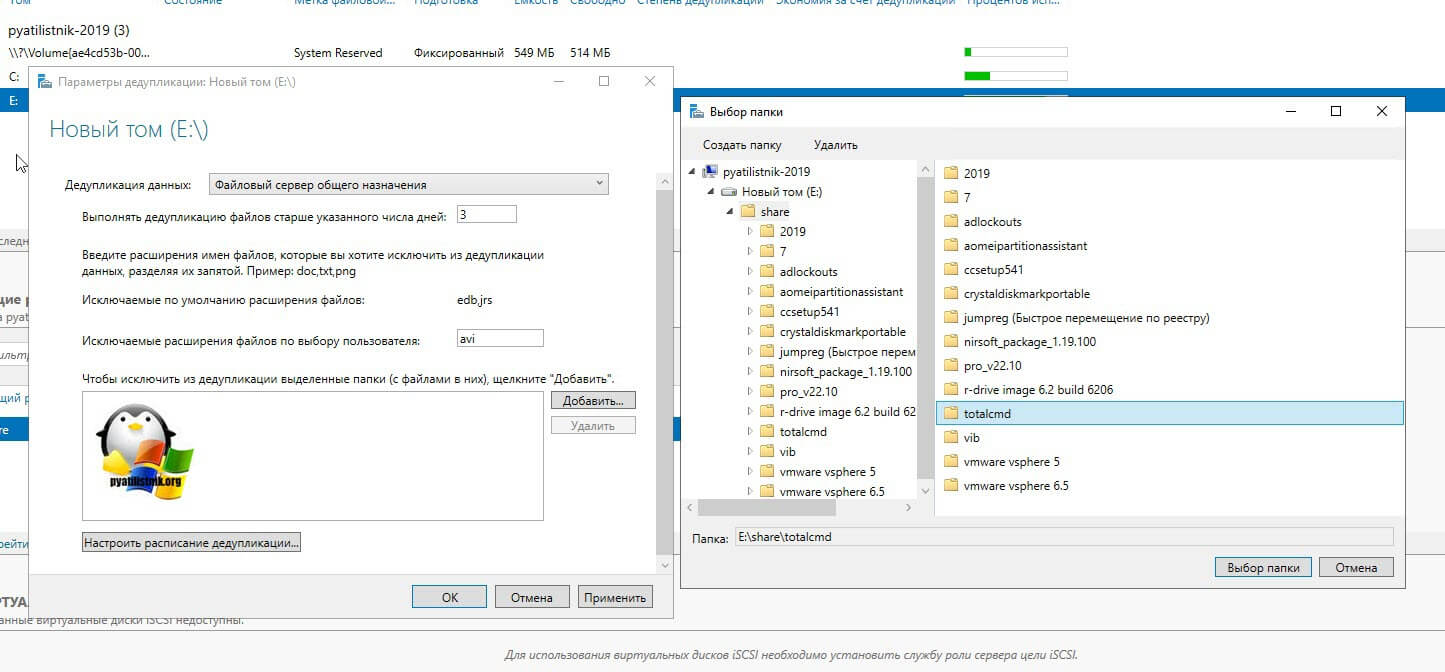
В списке исключения у вас будет выбранная папка. Чуть ниже будет очень полезная настройка, которая позволит вам управлять расписанием. Нажмите кнопку «Настроить расписание дедупликации (Set Deduplication Schedule)»
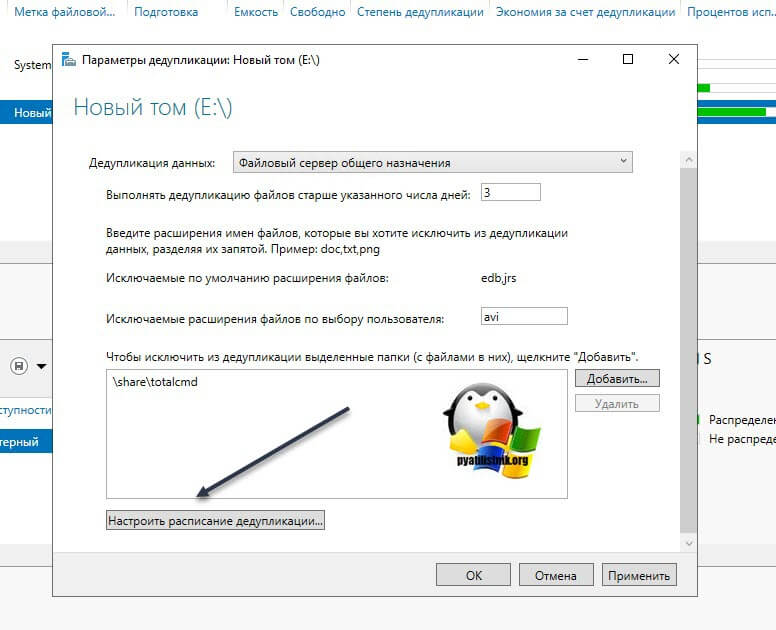
На выбор у вас есть возможность создавать два расписания, которые будут выполняться в фоновом режиме. Включаем галку «Включить фоновую оптимизацию (background optimization)». Далее, чтобы иметь возможность выбирать конкретные дни и время, вам необходимо выставить галку «Включить оптимизацию пропускной способности (Enable throughput optimization)». Первое задание у меня будет запускаться в 23-00 и выполняться до 9 утра. суммарно я на это выделил 10 часов, у вас эти цифры могут отличаться, тут нужно исходить от ваших условий.
Так же хочу отметить, что по данным компании Microsoft усредненная скорость дедупликации данных в Windows Server 2019 25 мб/с, это приблизительно 87 ГБ в час, это нужно учитывать на больших объемах данных. Так же если у вас в качестве томов выступают ISCSI ,то вам еще нужно учесть нагрузку на сеть.
Если вам необходимо запустить процедуру сразу, то тут вам в помощь PowerShell. Откройте оболочку повершела.
Import-Module Deduplication
Start-DedupJob -Volume E: -Type Optimization
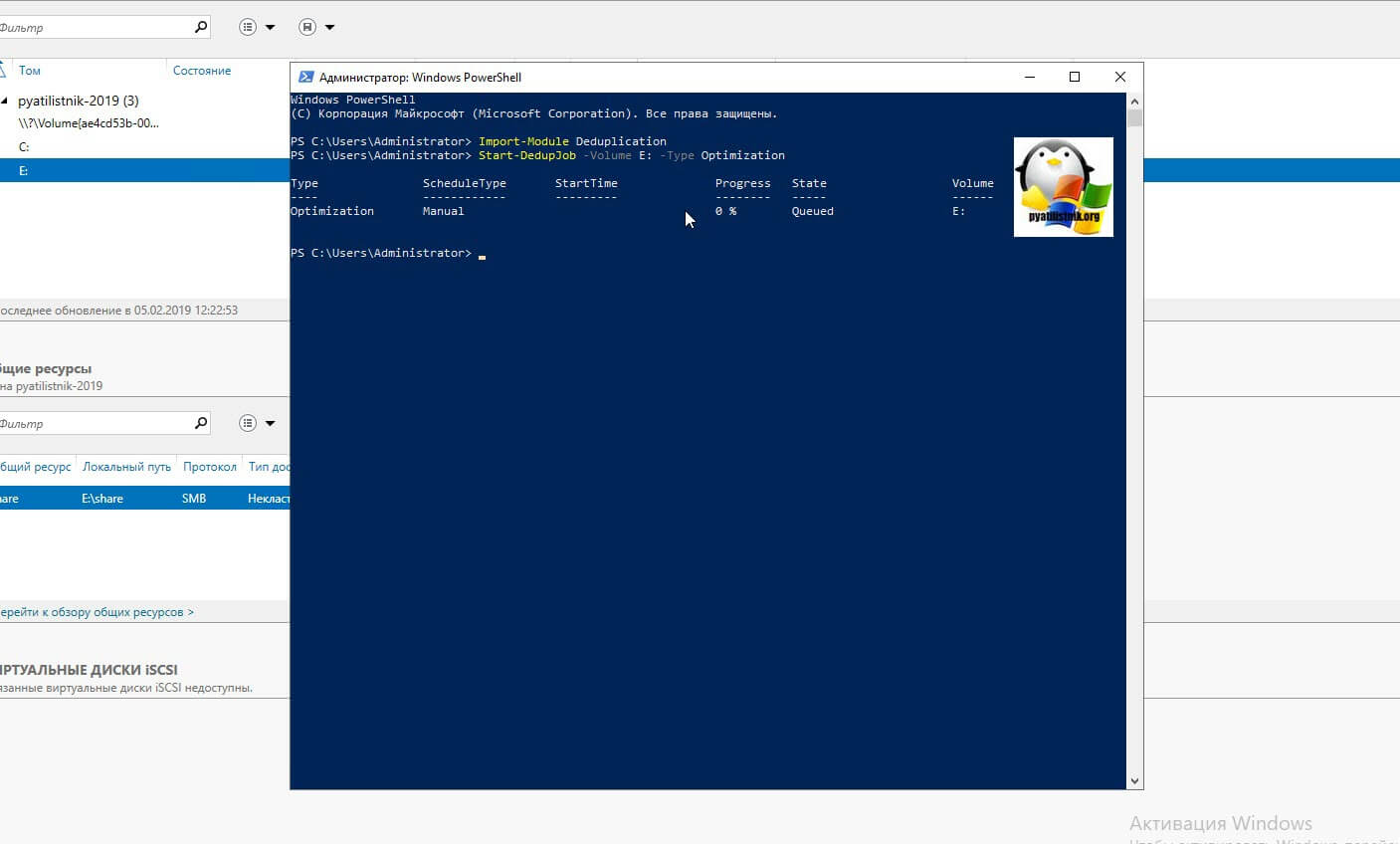 Первая команда импортирует нужный модуль, который содержит необходимые командлеты, вторая запустит немедленно дедупликацию на томе E:. Посмотреть статус выполнения хода дедупликации, вы сможете с помощью вот такой команды:
Первая команда импортирует нужный модуль, который содержит необходимые командлеты, вторая запустит немедленно дедупликацию на томе E:. Посмотреть статус выполнения хода дедупликации, вы сможете с помощью вот такой команды:
У вас будут столбы, где вы увидите, что тип задания «Manual (Запущенный вручную)», сам прогресс бар в процентах, статус и на каком томе выполняется задание.
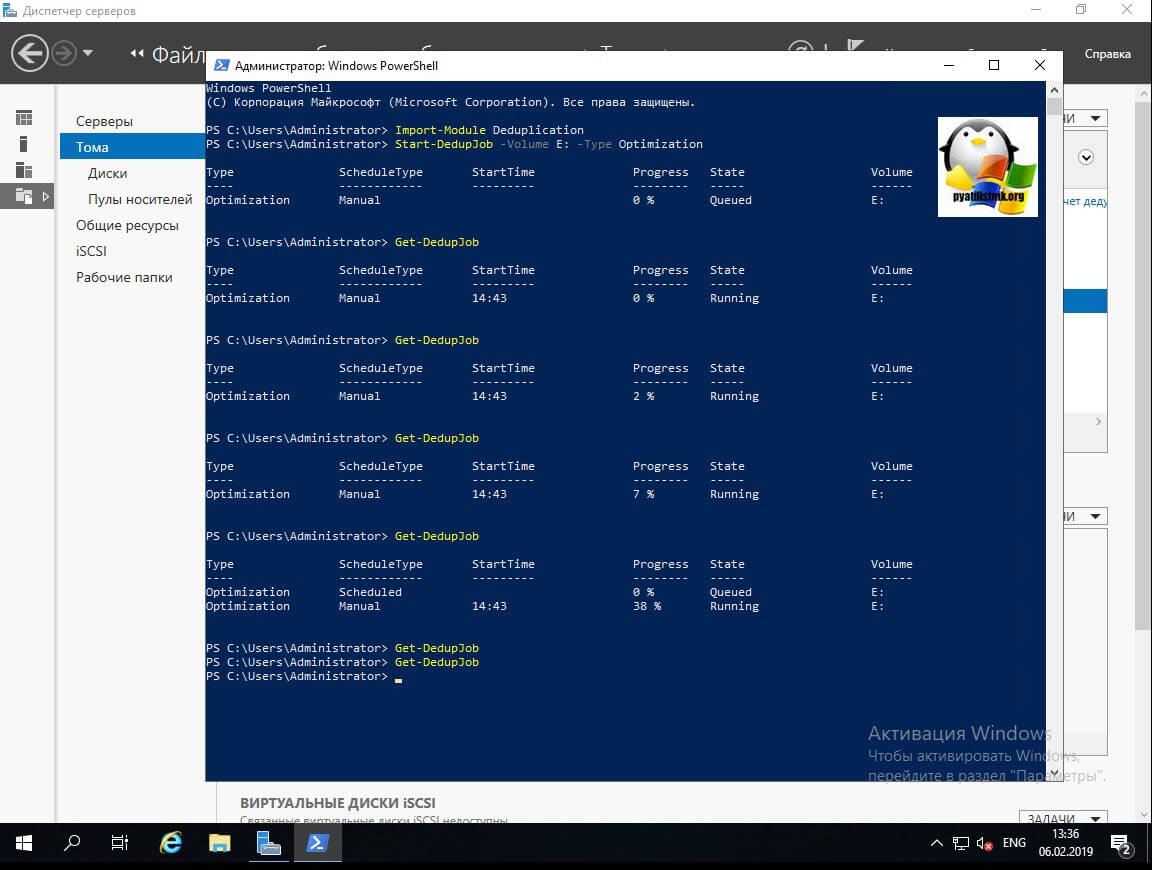
Теперь если посмотреть в оснастке диспетчера серверов степень дедупликации данных, то в моем случая я получил 33%, что весьма прилично.
Включение и настройка дедупликации через PowerShell
Графический метод, это хорошо, но все же большую свободу действий и возможностей нам компания Microsoft предоставляет, через использования сильного языка и его командлетов. Откройте оснастку Powershell. Первым делом импортируем модуль для нужных команд.
Import-Module ServerManager
Первым делом нужно включить саму дедупликацию и выбрать один из ее типов. Сделать, это можно командой:
Enable-DedupVolume -Volume «E:»
В результате на томе E: будет активированная дедупликация со стандартным типом «Файловый сервер общего назначения». Если нужно задать другие типы, то можно воспользоваться ключами:
- -UsageType HyperV — аналогично режиму «Сервер инфраструктуры виртуальных рабочих столов (VDI) (Virtual Desktop infrastructure VDI server)»
- Backup — Виртуализированный резервный сервер (Virtualized Backup Server), для виртуального DPM
- Default — Файловый сервер общего назначения (General puprose file server)
Подробнее можно почитать вот тут https://docs.microsoft.com/en-us/powershell/module/deduplication/enable-dedupvolume
Если в нужно явно задать режим работы, то сделайте командой:
Enable-DedupVolume -Name E: -UsageType Backup
Так же можно выполнить сразу для нескольких томов в Windows Server 2019:
Enable-DedupVolume -Volume «D:»,»E:»,»F:» -UsageType Default
Так же если у вас нет букв томов и вы знаете только GUID, то его так же можно использовать в командах:
Enable-DedupVolume -Volume «\?Volume{31f21dda-a644-1133-9541-806e6fg46966}»
Как отключить дедупликацию Windows
Простая задача, необходимо выключить и затем удалить роль дедупликации в Windows Server 2019. Если вы отключите дедупликацию данных с помощью графического интерфейса или Powershell, это на самом деле не отменит выполненную работу и дедуплицированные данные на текущий момент останутся. Хуже того, если вы отключили сервис, то вы не можете запустить команду очистки мусора (которая очищает данные, созданные с помощью технологии дедупликации).
Поэтому важно, чтобы вы оставили дедупликацию данных включенной, но сначала ИСКЛЮЧИЛИ весь диск. Затем выполните следующие две команды (которые будут выполняться в зависимости от количества имеющихся у вас данных). Первая команда исключает из процесса дедупликации раздел D:
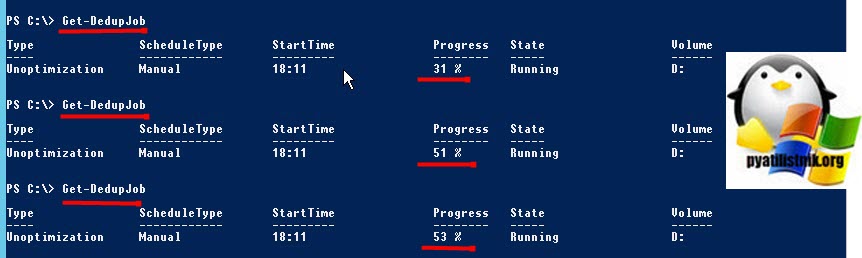
Start-DedupJob -Type Unoptimization -Volume D: -Full
Ключ -Full указывает, что задания по сборке мусора освобождают все удаленные или не связанные данные на томе. Если этот параметр не указан, задания по сборке мусора освобождают пространство после превышения системного порога удаления данных.

Если том не имеет достаточно места для хранения не оптимизированных данных, задание отмены оптимизации завершится сбоем.
Далее мониторим его статус, пока задание не будет выполнено:
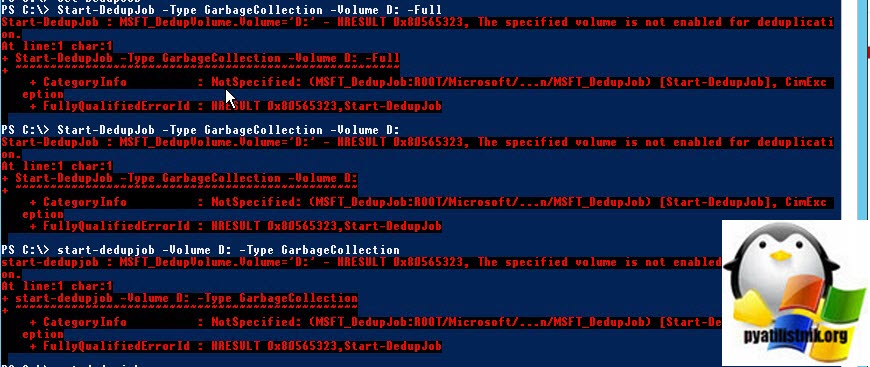
Поскольку задание по сбору мусора еще нужно запустить, нам нужно довольно нелогично включить дедупликацию для тома с помощью следующей команды
Enable-DedupVolume -Volume D:
В противном случае вы будите получать ошибку:
Start-DedupJob : MSFT_DedupVolume.Volume=’D:’ — HRESULT 0x80565323, The specified volume is not enabled for deduplicati
on.
At line:1 char:1
+ Start-DedupJob -Type GarbageCollection -Volume D: -Full
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (MSFT_DedupJob:ROOT/Microsoft/…n/MSFT_DedupJob) [Start-DedupJob], CimExc
eption
+ FullyQualifiedErrorId : HRESULT 0x80565323,Start-DedupJob
Как только это будет сделано, следующим шагом будет запуск следующей команды, чтобы запустить сборку мусора на томе
Start-DedupJob -Type GarbageCollection -Volume D: -Full
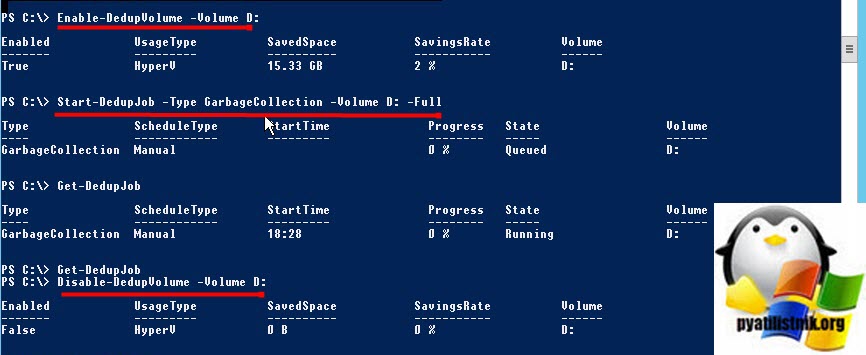
Наконец, после этого последний шаг — отключить дедупликацию тома с помощью следующей команды
Disable-DedupVolume -Volume D:
Data Deduplication (дедупликация данных) — это возможность уменьшать пространства за счет удаления одной части дублирующих данных. Впервые Microsoft выпустила такую возможность в Windows Server 2012 и технически она менялась вплоть до самой последней версии сервера 2019. Технология дедупликации реализована у множества брендов в том числе: HP, CISCO, IBM и VmWare.
Для чего нужна и как работает дедупликация
Если взять обычный файловый или бэкап сервер, то мы увидим большой объем полностью или частично дублирующих файлов. На файловых серверах это полные копии данных, которые хранят разные пользователи, а на бэкап серверах — это минимум файлы с ОС. С определенным интервалом происходит процесс сканирования блоков с данными в 32-128 Кб и проверка уникальности. Такие блоки так же называются чанками (chunk/куски) и это важно запомнить, так как это название вы будете видеть в Powershell. При нахождении одинаковых чанков они оба будут удалены и заменен ссылкой на уникальный чанк помещенный в специальное место. Такие ссылки будут помещены в папку System Volume Information, а блоки, с уникальными данными, в контейнеры. Все такие данные, в Windows Server, имеют возможность восстановления в случае критических повреждений.
Дедупликация работает по томам и в целом мы можем увидеть такую схему:
- Оптимизированные файлы, состоящие из ссылок на уникальные чанки;
- Чанки, организованные в контейнеры, которые сжимаются и помещаются в хранилище;
- Не оптимизированные файлы.
Бренды реализуют дедуликацию по-разному. Она может работать с целым файлом, блоком или битом. В Windows Server реализована только блочная дедупликация. Файловая дедупликация была реализована в Microsoft DPM, но в этом случае, файл измененный на бит, уже будет являться новым и это было бы оправдано в случаях бэкапа. В сетях можно увидеть битовую.
Картинки, которые так же немного демонстрирует описанный процесс:


Кроме реализации дедупликации на уровне томов, у некоторых брендов, она работает и на уровне сети. Вместо отправки файлов будут отправлены хэш суммы (SHA-1, SHA-2, SHA-256) чанков и если хэш будет совпадать с тем, что уже имеется на стороне принимающего сервера, он не будет перенесен. Похожая возможность, в Windos Server, реализована с помощью работы BranchCache и роли Data Deduplication.
Изменения в версиях
Дедупликация не работает на томах меньше чем 2 Гб.
Windows Server 2012 + r2
- файловая система только NTFS;
- поддержка томов до 10 Тб;
- не рекомендуется использовать с файлами объем которых достигает 1 Тб;
- 2012 не поддерживает VSS (не может работать с открытыми файлами) с 2012 r2 эта поддержка появилась;
- один режим работы.
Windows Server 2016
- файловая система только NTFS;
- поддержка томов до 64 Тб;
- дедупликация работает с первым 1 Тб данных у файла (ранее могли быть ошибки после 1 Тб данных, но исправилась после выпуска обновлений kb3216755, kb4025334, kb4013429);
- три режима работы;
- возможность доступна в Nano Server.
Windows Server 2019
- файловая система NTFS или ReFS;
- поддержка томов до 64 Тб;
- работа с первыми 4 Тб данных у файла (ранее могли быть ошибки после 1 Тб данных, но исправилась после выпуска обновлений kb3216755, kb4025334, kb4013429);
- три режима работы;
- интеграция с BranchCache;
- возможность доступна в Nano Server.
Процесс дедупликации происходит по расписанию, а не «на лету», и из-за этого есть общие рекомендации по размеру разделов. Если разделы будут больше описанных выше, то скорость работы сканирования может быть меньше чем обновление этих файлов. В версии 2016 в процесс дедупликации была добавлена парализация, что позволило увеличить скорость и общий объем работы для работы этой роли:

Если вы используете кластер, то роль должна быть установлена на каждую ноду.
Где и когда применять
Связи с причинами описанными выше есть рекомендации, где имеет смысл использовать роль:
- Файловые сервера
- VDI
- Архивы с бэкапом
Фактически вы не сможете использовать эту роль со следующими условиями (без учета разницы в версиях):
- файлы зашифрованные (EFS);
- файлы с расширенными атрибутами;
- размер файлов меньше чем 32 Кб;
- том является системным или загрузочным;
- тома не являющиеся дисками (сетевые папки, USB носители).
В теории вы можете работать с любыми остальными типами файлов и серверов, но дедупликация очень ресурсозатратный процесс и лучше следовать объемам, указанным выше. Допустим у вас на сервере много файлов формата mp4 и вы предполагаете, что существенная их часть разная — вы можете попробовать исключить их из анализа. Если сервер будет успевать обрабатывать остальные типы файлов, то вы включите файлы mp4 в анализ позже.
Так же не стоит использовать дедупликацию на базах данных и любых других данных с высоким I/O, так как они содержат мало дублирующих данных и часто меняются. Из-за этого процесс поиска уникальных данных, а следовательно и нагрузка на сервер, может проходить в пустую.
Дедупликация работает по расписанию и может использовать минимум и максимум мощностей. В зависимости от общего объема и мощности сервера разный процесс дедупликации (их 4) может занять как час, так и дни. Microsoft рекомендует использовать 10 Gb оперативной памяти на 10 Тb тома. Часть операций нужно делать после работы, какие-то в выходные — все индивидуально.
На некоторых программах бэкапа, например Veeam, тоже присутствует дедупликация архивов. Если вы храните такой бэкап на томе Windows, с такой же функцией, вам нужно выполнить дополнительные настройки. Игнорирование этого может привести к критическим ошибкам.
При копировании файлов между двумя серверами, с установленной ролью, они будут перенесены в дедуплицированном виде. При переносе на том, где этой роли нет — они будут сохранены в исходном состоянии.
Microsoft не рекомендует использовать robocopy, так как это может привести к повреждению файлов.
В клиентских версиях, например Windows 10, официально такой роли нет, но способ установки существует. Люди, которые выполняли такую процедуру, сообщали о проблемах с программами подразумевающие синхронизацию с внешними базами данных.
Установка
В панели Server Manager открываем мастер по установке ролей и компонентов:

Пропускаем первые три шага (область 1) или выбираем другой сервер если планируем устанавливать роль не на этот сервер (область 2):

На этапе выбора ролей сервера, во вкладе «Файловые службы и службы хранилища» и «Файловые службы и службы iSCSI» выбираем «Дедупликация данных»:

Раздел выбора компонентов не понадобится и его можно пропустить. На шаге подтверждения можно еще раз проверить выбранные операции и нажать кнопку установки:

Установка занимает несколько минут и без необходимости в последующей перезагрузке. Окно подтверждающее успешную установку можно закрыть:

Оценка потенциального освобождающегося места с DDPEval.exe
Вместе с установкой роли у появляется программа DDPEval.exe, позволяющая предварительно оценить пространство, которое будет освобождено в последующем.
Статистика, которую предоставляет Microsoft в зависимости от разных типов данных, примерно следующая:
- Документы пользователей — экономия 30-50%
- Установочные файлы — экономия 70-80%
- Файлы виртуализации — экономия 80-95%
- Файловые хранилища — экономия 50-60%

Для оценки места я поместил 3 одинаковых установочных архива с Exchange 2013 общим объемом 6 Гб на диск Е.
Открываем Powershell/CMD и пишем команду, которая имеет следующий синтаксис:
DDPEval.exe <раздел>
DDPEval.exe <раздел><папка>
# Пример
DDPEval.exe E:Folder1
По каким-то причинам у меня определилась Windows 10, хотя я использую Windows Server 2019
Как можно увидеть — экономия на полностью идентичных файлах в 69 % или 4.27 Gb.
Я удалил файлы с Exchange и поместил 3 разных образа Linux (Ubuntu, Debian, Centos):


Экономия в 2%.
И последний результат с 11 разными csv/xlsx/docx файлами. Экономия 51%:

Настройка роли
Возможность управлять ролью находится на вкладе «Файловые службы»:

Во вкладке по работе с разделов выберем один из них и нажмем правой кнопкой мыши. В выплывающей меню мы увидим «Настройка дедупликации данных»:

По умолчанию дедупликация отключена. У нас есть выбор из трех вариантов:
- Файловый сервер общего назначения;
- Сервер инфраструктуры виртуальных рабочих столов (VDI);
- Виртуализированный резервный сервер.
Каждый из этих режимов устанавливается с рекомендуемыми настройками и дальнейшие изменения можно пропустить:

Важной настройкой является установка возраста файла (область 1), который будет проходить процесс оптимизации. Новые файлы пользователей могут активно меняться в течение нескольких дней, что в пустую увеличит нагрузку на сервер при дедупликации, а затем не открываться вовсе. Если установить значение 0, то дедупликация не будет учитывать возраст файла вовсе.
В области 2 указываются расширения файлов для исключения из процессов дедупликации. Рекомендую установить несколько расширений, которые не несут значительную роль. Затем, через недели две, оценить нагрузку на сервер и, если она будет удовлетворительной, убрать исключение. Вы можете сделать и обратную операцию, добавив в исключения расширения уже после оценки нагрузки, но этот вариант не настолько очевиден как первый. Проблема будет в том, что исключенные файлы не раздедуплицируются автоматически (только с Powershell) и они все так же будут нуждаться в поддержке и ресурсах. В области 3 исключаются папки.

В окне расписания мы можем настроить следующее:
- Фоновая оптимизация (Enable background optimization) — включена по умолчанию. Работает с низким приоритетом не мешая основным процессам. При высокой нагрузке останавливается автоматически. Срабатывает один раз в час;
- Включить оптимизацию пропускной способности (Enable throughput optimization) — расписание, когда дедупликация может выполнятся без ограничения в ресурсах. Можно настроить на выходные дни например;
- Создать второе расписание оптимизации пропускной способности (Create a second schedule for throughput optimization) — расписание аналогично предыдущему. Можно настроить на вечернее время.

На этом настройки, которые выполняются через интерфейс заканчиваются. Если снять галочку, которая включает дедупликацию, все процессы поиска и дедупликации остановятся, но файлы не вернуться в исходное положение. Для обратного преобразования файлов нужно запускать процесс Unoptimization, который выполняется в Powershell и описан ниже.
Расширенные настройки с Powershell
С помощью Powershell мы можем установить роль и настроить ее сразу на множестве компьютеров. Для установки роли локально или удаленно можно использовать следующую команду:
Install-WindowsFeature -Name "FS-Data-Deduplication" -ComputerName "Имя компьютера" -IncludeAllSubFeature -IncludeManagementToolsСледующим способом мы увидим все команды модуля дедупликации:
Get-Command -Module Deduplication
Включение и настройка дедупликации для томов
Как уже говорилось выше, при настройке в GUI у нас есть три рекомендованных режима работы с уже установленным расписанием:
- HyperV;
- Backup;
- Default (файловый сервер, устанавливается по умолчанию).
Каждый из этих режимов устанавливается для одного или множества томов следующим путем:
Enable-DedupVolume -Volume 'E:','D:' -UsageType 'Default'
В некоторых командах может появится ошибка, которая связана с написанием буквы раздела со слэшем. Если у вас она тоже появится попробуйте исправить ‘E:’ на ‘E:’:
No MSFT_DedupVolume objects found with property ‘Volume’ equal to ‘E:’
Так мы узнаем на каких томах настроена дедупликация:
Get-DedupVolume
Так же как и в GUI мы можем ограничить обработку папок и файлов по их расширению. Для этого есть следующие аргументы:
- ExcludeFolder — ограничения на папки, например ‘E:Folder1’,’E:Folder2»
- ExcludeFileType — ограничения по расширениям, например ‘txt’,’jpg’;
- MinimumFileAgeDays — минимальный возраст файла в днях, который будет оптимизироваться.
Следующий пример установит эти настройки и вернет их:
Set-DedupVolume `
-Volume 'E:' `
-ExcludeFolder 'E:folder_exclude' `
-ExcludeFileType 'txt','rar' `
-MinimumFileAgeDays 15
Get-DedupVolume | Select *
По умолчанию дедуплкиция работает только с файлами больше чем 32Kb. В отличие от GUI это меняется в Powershell, но не в меньшую сторону. На примере ниже я установлю этот минимум для файлов в 1GB:
Set-DedupVolume `
-Volume 'E:' `
-MinimumFileSize 1GB
Get-DedupVolume | Select *
Есть еще несколько параметров, которые устанавливаются:
- ChunkRedundancyThreshold — устанавливает порог ссылок после которого будет создан еще один идентичный чанк. По умолчанию равен 100. С помощью этого параметра увеличивается избыточность. Проявляется она в более быстром и гарантированном (в случае повреждения) доступе файла. Не рекомендуется менять;
- InputOutputScale — установка значения I/O для распараллеливания процесса от 0 до 36. По умолчанию значение рассчитывается само;
- NoCompress — значению в $True или $False устанавливающая будет ли происходить сжатие;
- NoCompressionFileType — расширение файлов к которым не будет применяться сжатие;
- OptimizeInUseFiles — будут ли оптимизированы открытые файлы, например подключенные файлы VHDx;
- OptimizePartialFiles — если $True — будет работать блочная дедупликация. В ином случае будет работать файловая дедупликация;
- Verify — добавляет еще одну проверку идентичности чанков. Они будут сравниваться побайтно. Не могу сказать о ситуациях, где это могло бы пригодиться.
Для отключения используется следующая команда:
Disable-DedupVolume -Volume 'E:'
Отключенная дедупликация не конвертирует файлы в их исходное состояние. В примере выше у нас просто не будут оптимизироваться новые файлы и выполнятся задачи. Если к команде добавить параметр -DataAccess, то мы отключим доступ к файлам прошедшим через процесс дедупликации. О том как отменить дедупликацию полностью — будет рассказано далее.
Изменение расписаний
Дедупликация делится на 4 типа задач отдельно которые можно запустить в Powershell:
- Оптимизация (Optimization) — разбиение данных на блоки, их сравнение, сжатие и помещение в хранилище System Volume Information. По умолчанию происходит раз в час;
- Сбор мусора (GarbageCollection) — удаление устаревших фрагментов (например восстановление тех данных у которых нет дубликатов). По умолчанию происходит каждую субботу;
- Проверка целостности (Scrubbing) — обнаружение повреждений в хранилище блоков и их восстановление. По умолчанию происходит каждую субботу;
- Отмена оптимизации (Unoptimization)— отмена или отключение оптимизации на томе. Выполняется по требованию.
Каждое такое задание, а так же созданные вами лично, можно увидеть в планировщике задач. Там же можно увидеть время запуска и результат выполнения:

Например можно увидеть, что задача фоновой оптимизации запускается каждый час.
Более конкретно узнать время задач мы можем через получение расписания:
Get-DedupSchedule
Задания никогда не выполняются одновременно — только в процессе очереди.
Мы можем изменить каждое из этих заданий. Например процесс GarbageCollection является очень ресурсозатратным процессом и я хочу что бы его работа начиналась в пятницу в 22:00 (по умолчанию работает в субботу в 2:45 ночи), что бы точно завершилась к понедельнику. Я так же установлю параметр StopWhenSystemBusy, который остановит процесс очистки мусора если система будет сильно нагружена другой задачей. Я сделаю это так:
Set-DedupSchedule `
-Name 'WeeklyGarbageCollection' `
-Type 'GarbageCollection' `
-Enabled $True `
-StopWhenSystemBusy $True `
-Days 'Friday' `
-Start 22:00 `

Где:
- Name — имя процесса, который мы хотим изменить;
- Type — тип процесса. В нашем случае это сборка мусора (GarbageCollection);
- Enabled — будет ли включен этот процесс;
- StopWhenSystemBusy — остановится ли процесс, если сервер будет сильно нагружен другой задачей (затем попробует запустится снова);
- Days — дни, в которые этот процесс должен запускаться;
- Start — время запуска.
Есть еще параметры, которые есть не только у этого командлета, но и у других команд дедупликации:
- DurationHours — продолжительность работы задачи в часах, после которого он будет корректно завершен. По умолчанию равен 0, что означает работу до полного завершения без ограничения во времени.
- Full — параметр со значениями $True и $False. Зависит от того что указано в Type. Если мы выполняем сборку мусора, то этот параметр будет удалять все устаревшие данные сразу, а не до достижения определенного порога. При выполнении очистки (Scrubbing), если указан параметр Full, происходит проверка всех данных, а не только критически важных. В обоих случаях этот параметр стоит использовать раз в месяц.
- ReadOnly — при работе очистки не исправляет ошибки, а только уведомляет
Кроме этого, почти во всех командах при работе с дедупликацией есть настройка ресурсов, которые мы планируем выделять:
- Cores — число с количеством ядер (в процентном соотношении), которые будут участвовать в процессе;
- Memory — количество памяти от общего значения (в процентном соотношении);
- StopWhenSystemBusy — останавливает задачу, если сервер, в данный момент, сильно нагружен (возобновляет ее позже);
- Priority — указывает тип нагрузки на процессор (ввод, вывод) со значениями: Low, Normal, High;
- InputOutputThrottle — ограничения работы ввода вывода при троттлинге в значениях от 0 до 100,;
- InputOutputThrottleLevel — ограничения работы ввода вывода при троттлинге со следующими значениями: None, Low, Medium, High. InputOutputThrottle имеет более высокий приоритет и при установке двух аргументов — InputOutputThrottleLevel может не работать.
- ThrottleLimit — указывает предел троттлинга. Если указан 0, то расчет будет выполнен автоматически.
На примере параметров выше я создам новую задачу по оптимизации. Она будет проходить в будни, после 21:00, с нагрузкой в 70% от максимальной на протяжении 8 часов:
New-DedupSchedule `
-Name 'Оптимизация по будням' `
-Cores 80 `
-Days Monday,Tuesday,Wednesday,Thursday,Friday `
-DurationHours 8 `
-InputOutputThrottleLevel Medium `
-Priority Normal `
-Memory 80 `
-Start 21:00 `
-Type 'Optimization' `
-StopWhenSystemBusy `

Обращу внимание, что мы можем не писать все эти настройки, а просто копировать их используя обычные методы Powershell. Так я создам копию задачи очистки (Scrubbing), которая будет дополнена ключом Full и отключена по умолчанию:
Get-DedupSchedule -Name '*Scrub*' | New-DedupSchedule `
-Name 'Полная проверка целостности раз в месяц' `
-Full `
-Disable `
Так же можно и удалять задачи:
Get-DedupSchedule -Name '*Полная*' | Remove-DedupSchedule
# или
Remove-DedupSchedule -Name '*Полная*'
Если вы убрали дедупликацию на томе и планируете обратить файлы в исходное состояние вы можете выполнить следующую команду установив свои настройки:
New-DedupSchedule -Type UnoptimizationУчитывайте, что вам потребуется больше свободного пространства для файлов (иначе дедупликация остановится с ошибкой) и процесс займет много ресурсов и времени. Копирование данных на другой том так же возможен и в этом случае файл тоже вернется в исходное состояние.
Запуск отдельных задач
Предыдущий пример, где мы устанавливали параметр Full, для проверки целостности всей базы, был не очень удачный. Дело в том, что мы можем устанавливать расписание только на неделю, а такая проверка рекомендуется раз в месяц. Для исправления этой ситуации мы можем использовать разовые задачи. Так я создам и запущу похожую задачу:
Start-DedupJob `
-Full `
-Volume 'E:' `
-Type 'Scrubbing'
Вернуть состояние задачи можно так:
Get-DedupJob
Если у вас есть настроенное расписание, то вы тоже его можете скопировать и запустить т.е. использовать как шаблон. Такая возможность явно не планировалась разработчиками и поэтому могут быть ошибки на этапе запуска. Например у меня была такие ошибки:
- Exception calling «EndProcessing» with «0» argument(s)
- Start-DedupJob : MSFT_DedupVolume.Volume=’
Одна из них была связана с отсутствием буквы раздела, так как я его не указал. Я дополнил параметры и все сработало корректно. Так же как и на примерах выше мы можем исправлять шаблон из планировщика как хотим. Ошибки могут быть разными, но они достаточно ясные и легко исправляются:
Get-DedupSchedule -Name '*полная проверка*' | Start-DedupJob -InputOutputThrottleLevel Low -Volume 'E:'
Так же как и при создании запланированной задачи мы можем установить следующие параметры (более детально они описаны выше):
- Cores
- Full
- InputOutputThrottle
- InputOutputThrottleLevel
- Memory
- Priority
- ReadOnly
- StopWhenSystemBusy
- ThrottleLimit
- Type
А эти параметры есть только у Start-DedupSchedule:
- Preempt — форсированный запуск задачи, отменяющий иные;
- Timestamp — работает только с задачами типа ‘Unoptimization’ и принимает значения типа данных DateTime. Отменяет оптимизацию файлов оптимизированных с указанной даты;
- Volume — можно указать один или несколько томов. Можно указывать буквы формата ‘E:’, ID и GUID;
- Wait — в фоне будет отображаться процесс задачи и ее результат. Пример ниже.

Пример отмены задач:
Get-DedupJob -Type Scrubbing | Stop-DedupJob
# или
Stop-DedupJob -Volume 'E:','C:'Отмену дедупликации вы так же можете запустить задачей:
Start-DedupJob -Type UnoptimizationСтатус дедупликации
Следующая команда вернет текущий статус дедупликации:
# Сокращенный вариант
Get-DedupStatus
# Полный отчет
Get-DedupStatus | select *
Предыдущая команда возвращает закэшированные данные, но если вы хотите получить наиболее актуальную информацию вы можете выполнить следующую команду:
# Для всех томов
Update-DedupStatus
# Для одного тома
Update-DedupStatus -Volume 'E:'
# Возвращение полной актуальной информации по тому
Update-DedupStatus -Volume 'E:' | SELECT *
Следующая команда вернет время последнего выполнения каждого из процессов дедупликации:
Get-DedupStatus -Volume 'E:' | select -Property "*time*" | fl
Эта команда вернет информацию по работе с файлами:
Get-DedupStatus -Volume 'E:' | select -Property "*file*",'s*rate*' | fl
Где:
- InPolicyFilesCount — количество файлов, которые подходят для оптимизации;
- InPolicyFilesSize — общий размер файлов, которые подходят для оптимизации;
- OptimizedFilesCount — количество файлов, которые были оптимизированы;
- OptimizedFilesSavingRate — процент оптимизированных файлов относительно всех файлов которые подходят под установленные параметры;
- OptimizedFilesSize — общий размер оптимизированных файлов.
Более точно эти данные отображаются после процесса сборки мусора и оптимизации.
Следующая команда вернет данные из базы дедупликации по определенному тому:
Get-DedupMetadata -Volume 'E:'
Если такой запрос завершится ошибкой, то скорее всего, в данный момент, происходит один из процессов дедупликации, который меняет эти метаданные.
По выводу мы можем увидеть:
- DataChunkCount — количество чанков, размером 32-128 Кб на одном томе;
- DataContainerCount — количество контейнеров;
- DataChunkAverageSize — средний размер одного чанка (размер контейнера поделенный на количество чанков);
- TotalChunkStoreSize — размер хранилища;
- CorruptionLogEntryCount — количество ошибок на томе.
Свойства типа «Stream*» скорее всего показывают данные по открытым файлам или проходящие через Volume Shadow Copy.
Если будет необходимость в освобождения места (переносом или удалением) подсчет потенциально освобождающегося пространства будет сложной задачей. Связано это с тем, что не ясно количество дедуплицированных файлов (они могут быть в трех, четырех копиях, в разных местах и т.д.). В этом случае можно использовать команду Measure-DedupFileMetadata:
Measure-DedupFileMetadata -Path 'E:New folder'
Где:
- FilesCount — количество файлов на всем томе;
- OptimizedFilesCount — количество оптимизированных файлов на всем томе;
- Size — суммарный размер всех файлов;
- DedupSize — итоговый размер дедуплицированных файлов в этой папке;
Восстановление дедуплицированных файлов
Команда Expand-DedupFile восстанавливает файл, который был оптимизирован в его исходное место. Такая операция может понадобится, когда стороннее приложение (например программы бэкапа) не могут корректно работать с файлом. Важным моментом восстановления таких файлов является достаточное количество места на диске. Следующим образом я восстановлю два файла в их исходное местоположение:
Expand-DedupFile -Path 'E:New folderOtchet2020.doc','E:New folder3285.wav'Никакого вывода команда не выдает, но если файл не был дедуплицирован, то вы получите ошибку:
Expand-DedupFile : MSFT_DedupVolume.Path=’E:file1′ — HRESULT 0x80070057, The parameter is incorrect.
…
Теги:
#powershell
#дедупликация
#windows server

Data Deduplication (дедупликация данных) — это возможность уменьшать пространства за счет удаления одной части дублирующих данных. Впервые Microsoft выпустила такую возможность в Windows Server 2012 и технически она менялась вплоть до самой последней версии сервера 2019. Технология дедупликации реализована у множества брендов в том числе: HP, CISCO, IBM и VmWare.
Содержание
- Для чего нужна и как работает дедупликация
- Изменения в версиях
- Где и когда применять
- Где нельзя применять
- Установка
- Оценка потенциального освобождающегося места с DDPEval.exe
- Настройка роли
- Расширенные настройки с Powershell
- Включение и настройка дедупликации для томов
- Изменение расписаний
- Мгновенный запуск дедупликации
- Статус дедупликации
- Восстановление дедуплицированных файлов
- Отключение Deduplication
- Где найти логи Deduplication
- Восстановление данных с HDD после дедупликации Windows Server
- Дедуплицированные папки весят 0 байт
- Дудуплицированные файлы весят 0 байт
Для чего нужна и как работает дедупликация
Если взять обычный файловый или бэкап сервер, то мы увидим большой объем полностью или частично дублирующих файлов. На файловых серверах это полные копии данных, которые хранят разные пользователи, а на бэкап серверах — это минимум файлы с ОС. С определенным интервалом происходит процесс сканирования блоков с данными в 32-128 Кб и проверка уникальности. Такие блоки так же называются чанками (chunk/куски) и это важно запомнить, так как это название вы будете видеть в Powershell. При нахождении одинаковых чанков они оба будут удалены и заменен ссылкой на уникальный чанк помещенный в специальное место. Такие ссылки будут помещены в папку System Volume Information, а блоки, с уникальными данными, в контейнеры. Все такие данные, в Windows Server, имеют возможность восстановления в случае критических повреждений.
Дедупликация работает по томам и в целом мы можем увидеть такую схему:
- Оптимизированные файлы, состоящие из ссылок на уникальные чанки;
- Чанки, организованные в контейнеры, которые сжимаются и помещаются в хранилище;
- Не оптимизированные файлы.
Бренды реализуют дедуликацию по-разному. Она может работать с целым файлом, блоком или битом. В Windows Server реализована только блочная дедупликация. Файловая дедупликация была реализована в Microsoft DPM, но в этом случае, файл измененный на бит, уже будет являться новым и это было бы оправдано в случаях бэкапа. В сетях можно увидеть битовую.
Картинки, которые так же немного демонстрирует описанный процесс:


Кроме реализации дедупликации на уровне томов, у некоторых брендов, она работает и на уровне сети. Вместо отправки файлов будут отправлены хэш суммы (SHA-1, SHA-2, SHA-256) чанков и если хэш будет совпадать с тем, что уже имеется на стороне принимающего сервера, он не будет перенесен. Похожая возможность, в Windos Server, реализована с помощью работы BranchCache и роли Data Deduplication.
Изменения в версиях
Дедупликация не работает на томах меньше чем 2 Гб.
Windows Server 2012 + r2
- файловая система только NTFS;
- поддержка томов до 10 Тб;
- не рекомендуется использовать с файлами объем которых достигает 1 Тб;
- 2012 не поддерживает VSS (не может работать с открытыми файлами) с 2012 r2 эта поддержка появилась;
- один режим работы.
Windows Server 2016
- файловая система только NTFS;
- поддержка томов до 64 Тб;
- дедупликация работает с первым 1 Тб данных у файла (ранее могли быть ошибки после 1 Тб данных, но исправилась после выпуска обновлений kb3216755, kb4025334, kb4013429);
- три режима работы;
- возможность доступна в Nano Server.
Windows Server 2019
- файловая система NTFS или ReFS;
- поддержка томов до 64 Тб;
- работа с первыми 4 Тб данных у файла (ранее могли быть ошибки после 1 Тб данных, но исправилась после выпуска обновлений kb3216755, kb4025334, kb4013429);
- три режима работы;
- интеграция с BranchCache;
- возможность доступна в Nano Server.

Если вы используете кластер, то роль должна быть установлена на каждую ноду.
Где и когда применять
Связи с причинами описанными выше есть рекомендации, где имеет смысл использовать роль:
- Файловые сервера
- VDI
- Архивы с бэкапом ( Не рекомендую)
Фактически вы не сможете использовать эту роль со следующими условиями (без учета разницы в версиях):
- файлы зашифрованные (EFS);
- файлы с расширенными атрибутами;
- размер файлов меньше чем 32 Кб;
- том является системным или загрузочным;
- тома не являющиеся дисками (сетевые папки, USB носители).
В теории вы можете работать с любыми остальными типами файлов и серверов, но дедупликация очень ресурсозатратный процесс и лучше следовать объемам, указанным выше. Допустим у вас на сервере много файлов формата mp4 и вы предполагаете, что существенная их часть разная — вы можете попробовать исключить их из анализа. Если сервер будет успевать обрабатывать остальные типы файлов, то вы включите файлы mp4 в анализ позже.
Так же не стоит использовать дедупликацию на базах данных и любых других данных с высоким I/O, так как они содержат мало дублирующих данных и часто меняются. Из-за этого процесс поиска уникальных данных, а следовательно и нагрузка на сервер, может проходить в пустую.
Дедупликация работает по расписанию и может использовать минимум и максимум мощностей. В зависимости от общего объема и мощности сервера разный процесс дедупликации (их 4) может занять как час, так и дни. Microsoft рекомендует использовать 10 Gb оперативной памяти на 10 Тb тома. Часть операций нужно делать после работы, какие-то в выходные — все индивидуально.
На некоторых программах бэкапа, например Veeam, тоже присутствует дедупликация архивов. Если вы храните такой бэкап на томе Windows, с такой же функцией, вам нужно выполнить дополнительные настройки. Игнорирование этого может привести к критическим ошибкам.
При копировании файлов между двумя серверами, с установленной ролью, они будут перенесены в дедуплицированном виде. При переносе на том, где этой роли нет — они будут сохранены в исходном состоянии.
Microsoft не рекомендует использовать robocopy, так как это может привести к повреждению файлов.
В клиентских версиях, например Windows 10, официально такой роли нет, но способ установки существует. Люди, которые выполняли такую процедуру, сообщали о проблемах с программами подразумевающие синхронизацию с внешними базами данных.
Где нельзя применять
Дедупликация была создана для томов данных NTFS, она не поддерживает загрузочные или системные диски и не может использоваться с общими томами кластера (CSV). Не поддерживает дедупликацию работающих виртуальных машин или раюотающих баз данных SQL , также на диске не должен находится файл подкачки
Установка
В панели Server Manager открываем мастер по установке ролей и компонентов:

Пропускаем первые три шага (область 1) или выбираем другой сервер если планируем устанавливать роль не на этот сервер (область 2):

На этапе выбора ролей сервера, во вкладе «Файловые службы и службы хранилища» и «Файловые службы и службы iSCSI» выбираем «Дедупликация данных»:

Раздел выбора компонентов не понадобится и его можно пропустить. На шаге подтверждения можно еще раз проверить выбранные операции и нажать кнопку установки:

Установка занимает несколько минут и без необходимости в последующей перезагрузке. Окно подтверждающее успешную установку можно закрыть:

Или выполните следующую команду PowerShell:Install-WindowsFeature -Name FS-Data-Deduplication -IncludeAllSubfeature -IncludeManagementTools

Оценка потенциального освобождающегося места с DDPEval.exe
Вместе с установкой роли у появляется программа DDPEval.exe, позволяющая предварительно оценить пространство, которое будет освобождено в последующем.
Статистика, которую предоставляет Microsoft в зависимости от разных типов данных, примерно следующая:
- Документы пользователей — экономия 30-50%
- Установочные файлы — экономия 70-80%
- Файлы виртуализации — экономия 80-95%
- Файловые хранилища — экономия 50-60%

Если вы сомневаетесь стоит ли вам настраивать дедупликацию на вашем сервере, но хотите узнать сколько дискового пространства вы можете сэкономить за счет ее активации, то можно использовать ddpeval.exe
Диск не должен быть включен в дедупликацию , иначе будет ошибка
ERROR: Evaluation not supported on system, boot or Data Deduplication enabled volumes.
ddpeval.exe вы можете найти в папке WindowsSystem32 после установки роли Data Deduplication.
Предположим, у нас есть папка в которой лежит 3 Full бэкапа, сделанные средствами wbadmin, общим объемом 2.18 tb.
Нас интересует сколько мы сэкономим места за счет использования дедупликации.
Открываем CMD. Переходим в папку где находится ddpeval.exe и выполняем несложную команду
ddpeval E:backup1msk-exch01 /V /O:C:TempDedupEval.txt
где:
‘E:backup1msk-exch01’ — папку которую мы анализируем,
/V — как обычно, ключ расширенной обратной связи,
/O: — путь к файлу в который будет записан отчет по анализу экономии дискового пространств.
Известно что самый большой процент экономии места от дедупликации достигается на резервных копиях(если это не инкриментальные копии), за счет того что основная часть РК остается неизменной.

В таблице видно что самый большой коэффициент имеют образы виртуальных машин, а wbadmin как раз и создает файлы виртуальных дисков в формате vhdx.
Результат анализа папки с бэкапами

Нам предлагают ознакомиться с двумя вариантами анализа: с сжатием и без.
Мы можем видеть что экономия места после проведения дедупликации будет достаточно значительной — не менее 700 гигабайт.
И последний результат с 11 разными csv/xlsx/docx файлами. Экономия 51%:

Настройка роли
Возможность управлять ролью находится на вкладе «Файловые службы»:

Во вкладке по работе с разделов выберем один из них и нажмем правой кнопкой мыши. В выплывающей меню мы увидим «Настройка дедупликации данных»:

По умолчанию дедупликация отключена. У нас есть выбор из трех вариантов:
- Файловый сервер общего назначения;
- Сервер инфраструктуры виртуальных рабочих столов (VDI);
- Виртуализированный резервный сервер.
Каждый из этих режимов устанавливается с рекомендуемыми настройками и дальнейшие изменения можно пропустить:

Важной настройкой является установка возраста файла (область 1), который будет проходить процесс оптимизации (Те файлы которые больше 3 дней лежат на файловом сервере). Новые файлы пользователей могут активно меняться в течение нескольких дней, что в пустую увеличит нагрузку на сервер при дедупликации, а затем не открываться вовсе. Если установить значение 0, то дедупликация не будет учитывать возраст файла вовсе.
В области 2 указываются расширения файлов для исключения из процессов дедупликации. Рекомендую установить несколько расширений, которые не несут значительную роль. Затем, через недели две, оценить нагрузку на сервер и, если она будет удовлетворительной, убрать исключение. Вы можете сделать и обратную операцию, добавив в исключения расширения уже после оценки нагрузки, но этот вариант не настолько очевиден как первый. Проблема будет в том, что исключенные файлы не раздедуплицируются автоматически (только с Powershell) и они все так же будут нуждаться в поддержке и ресурсах. В области 3 исключаются папки.

В окне расписания мы можем настроить следующее:
- Фоновая оптимизация (Enable background optimization) — включена по умолчанию. Работает с низким приоритетом не мешая основным процессам. При высокой нагрузке останавливается автоматически. Срабатывает один раз в час;
- Включить оптимизацию пропускной способности (Enable throughput optimization) — расписание, когда дедупликация может выполнятся без ограничения в ресурсах. Можно настроить на выходные дни например;
- Создать второе расписание оптимизации пропускной способности (Create a second schedule for throughput optimization) — расписание аналогично предыдущему. Можно настроить на вечернее время.

На этом настройки, которые выполняются через интерфейс заканчиваются. Если снять галочку, которая включает дедупликацию, все процессы поиска и дедупликации остановятся, но файлы не вернуться в исходное положение. Для обратного преобразования файлов нужно запускать процесс Unoptimization, который выполняется в Powershell и описан ниже.
Расширенные настройки с Powershell
С помощью Powershell мы можем установить роль и настроить ее сразу на множестве компьютеров. Для установки роли локально или удаленно можно использовать следующую команду:
Install-WindowsFeature -Name "FS-Data-Deduplication" -ComputerName "Имя компьютера" -IncludeAllSubFeature -IncludeManagementTools
Следующим способом мы увидим все команды модуля дедупликации:
Get-Command -Module Deduplication

Включение и настройка дедупликации для томов
Как уже говорилось выше, при настройке в GUI у нас есть три рекомендованных режима работы с уже установленным расписанием:
- HyperV;
- Backup;
- Default (файловый сервер, устанавливается по умолчанию).
Каждый из этих режимов устанавливается для одного или множества томов следующим путем:
Enable-DedupVolume -Volume 'E:','D:' -UsageType 'Default'

В некоторых командах может появится ошибка, которая связана с написанием буквы раздела со слэшем. Если у вас она тоже появится попробуйте исправить ‘E:’ на ‘E:’:
No MSFT_DedupVolume objects found with property ‘Volume’ equal to ‘E:’
Так мы узнаем на каких томах настроена дедупликация:
Get-DedupVolume

Так же как и в GUI мы можем ограничить обработку папок и файлов по их расширению. Для этого есть следующие аргументы:
- ExcludeFolder — ограничения на папки, например ‘E:Folder1’,’E:Folder2»
- ExcludeFileType — ограничения по расширениям, например ‘txt’,’jpg’;
- MinimumFileAgeDays — минимальный возраст файла в днях, который будет оптимизироваться.
Следующий пример установит эти настройки и вернет их:
Set-DedupVolume `
-Volume 'E:' `
-ExcludeFolder 'E:folder_exclude' `
-ExcludeFileType 'txt','rar' `
-MinimumFileAgeDays 15
Get-DedupVolume | Select *
По умолчанию дедуплкиция работает только с файлами больше чем 32Kb. В отличие от GUI это меняется в Powershell, но не в меньшую сторону. На примере ниже я установлю этот минимум для файлов в 1GB:
Set-DedupVolume `
-Volume 'E:' `
-MinimumFileSize 1GB
Get-DedupVolume | Select *
Есть еще несколько параметров, которые устанавливаются:
- ChunkRedundancyThreshold — устанавливает порог ссылок после которого будет создан еще один идентичный чанк. По умолчанию равен 100. С помощью этого параметра увеличивается избыточность. Проявляется она в более быстром и гарантированном (в случае повреждения) доступе файла. Не рекомендуется менять;
- InputOutputScale — установка значения I/O для распараллеливания процесса от 0 до 36. По умолчанию значение рассчитывается само;
- NoCompress — значению в $True или $False устанавливающая будет ли происходить сжатие;
- NoCompressionFileType — расширение файлов к которым не будет применяться сжатие;
- OptimizeInUseFiles — будут ли оптимизированы открытые файлы, например подключенные файлы VHDx;
- OptimizePartialFiles — если $True — будет работать блочная дедупликация. В ином случае будет работать файловая дедупликация;
- Verify — добавляет еще одну проверку идентичности чанков. Они будут сравниваться побайтно. Не могу сказать о ситуациях, где это могло бы пригодиться.
Для отключения используется следующая команда:
Disable-DedupVolume -Volume 'E:'

Отключенная дедупликация не конвертирует файлы в их исходное состояние. В примере выше у нас просто не будут оптимизироваться новые файлы и выполнятся задачи. Если к команде добавить параметр -DataAccess, то мы отключим доступ к файлам прошедшим через процесс дедупликации. О том как отменить дедупликацию полностью — будет рассказано далее.
Изменение расписаний
Дедупликация делится на 4 типа задач отдельно которые можно запустить в Powershell:
- Оптимизация (Optimization) — разбиение данных на блоки, их сравнение, сжатие и помещение в хранилище System Volume Information. По умолчанию происходит раз в час;
- Сбор мусора (GarbageCollection) — удаление устаревших фрагментов (например восстановление тех данных у которых нет дубликатов). По умолчанию происходит каждую субботу;
- Проверка целостности (Scrubbing) — обнаружение повреждений в хранилище блоков и их восстановление. По умолчанию происходит каждую субботу;
- Отмена оптимизации (Unoptimization)— отмена или отключение оптимизации на томе. Выполняется по требованию.
Каждое такое задание, а так же созданные вами лично, можно увидеть в планировщике задач. Там же можно увидеть время запуска и результат выполнения:

Например можно увидеть, что задача фоновой оптимизации запускается каждый час.
Более конкретно узнать время задач мы можем через получение расписания:
Get-DedupSchedule

Задания никогда не выполняются одновременно — только в процессе очереди.
Мы можем изменить каждое из этих заданий. Например процесс GarbageCollection является очень ресурсозатратным процессом и я хочу что бы его работа начиналась в пятницу в 22:00 (по умолчанию работает в субботу в 2:45 ночи), что бы точно завершилась к понедельнику. Я так же установлю параметр StopWhenSystemBusy, который остановит процесс очистки мусора если система будет сильно нагружена другой задачей. Я сделаю это так:
Set-DedupSchedule `
-Name 'WeeklyGarbageCollection' `
-Type 'GarbageCollection' `
-Enabled $True `
-StopWhenSystemBusy $True `
-Days 'Friday' `
-Start 22:00 `
Где:
- Name — имя процесса, который мы хотим изменить;
- Type — тип процесса. В нашем случае это сборка мусора (GarbageCollection);
- Enabled — будет ли включен этот процесс;
- StopWhenSystemBusy — остановится ли процесс, если сервер будет сильно нагружен другой задачей (затем попробует запустится снова);
- Days — дни, в которые этот процесс должен запускаться;
- Start — время запуска.
Есть еще параметры, которые есть не только у этого командлета, но и у других команд дедупликации:
- DurationHours — продолжительность работы задачи в часах, после которого он будет корректно завершен. По умолчанию равен 0, что означает работу до полного завершения без ограничения во времени.
- Full — параметр со значениями $True и $False. Зависит от того что указано в Type. Если мы выполняем сборку мусора, то этот параметр будет удалять все устаревшие данные сразу, а не до достижения определенного порога. При выполнении очистки (Scrubbing), если указан параметр Full, происходит проверка всех данных, а не только критически важных. В обоих случаях этот параметр стоит использовать раз в месяц.
- ReadOnly — при работе очистки не исправляет ошибки, а только уведомляет
Кроме этого, почти во всех командах при работе с дедупликацией есть настройка ресурсов, которые мы планируем выделять:
- Cores — число с количеством ядер (в процентном соотношении), которые будут участвовать в процессе;
- Memory — количество памяти от общего значения (в процентном соотношении);
- StopWhenSystemBusy — останавливает задачу, если сервер, в данный момент, сильно нагружен (возобновляет ее позже);
- Priority — указывает тип нагрузки на процессор (ввод, вывод) со значениями: Low, Normal, High;
- InputOutputThrottle — ограничения работы ввода вывода при троттлинге в значениях от 0 до 100,;
- InputOutputThrottleLevel — ограничения работы ввода вывода при троттлинге со следующими значениями: None, Low, Medium, High. InputOutputThrottle имеет более высокий приоритет и при установке двух аргументов — InputOutputThrottleLevel может не работать.
- ThrottleLimit — указывает предел троттлинга. Если указан 0, то расчет будет выполнен автоматически.
Аналогия команды с другими ключами которая описана ниже
Задание должно запускаться в 9:00 с понедельника по пятницу и работать 11 часов, с нормальным приоритетом, использовать не более 20% ОЗУ и 20% ЦП:
New-DedupSchedule -Name ThroughputOptimization -Type Optimization -Days @(1,2,3,4,5) -DurationHours 11 -Start (Get-Date ″12/8/2016 9:00 PM″) -Memory 20 -Cores 20 -Priority NormalНа примере параметров выше я создам новую задачу по оптимизации. Она будет проходить в будни, после 21:00, с нагрузкой в 70% от максимальной на протяжении 8 часов:
New-DedupSchedule `
-Name 'Оптимизация по будням' `
-Cores 80 `
-Days Monday,Tuesday,Wednesday,Thursday,Friday `
-DurationHours 8 `
-InputOutputThrottleLevel Medium `
-Priority Normal `
-Memory 80 `
-Start 21:00 `
-Type 'Optimization' `
-StopWhenSystemBusy `
Обращу внимание, что мы можем не писать все эти настройки, а просто копировать их используя обычные методы Powershell. Так я создам копию задачи очистки (Scrubbing), которая будет дополнена ключом Full и отключена по умолчанию:
Get-DedupSchedule -Name '*Scrub*' | New-DedupSchedule `
-Name 'Полная проверка целостности раз в месяц' `
-Full `
-Disable `
Так же можно и удалять задачи:
Get-DedupSchedule -Name '*Полная*' | Remove-DedupSchedule
# или
Remove-DedupSchedule -Name '*Полная*'
Если вы убрали дедупликацию на томе и планируете обратить файлы в исходное состояние вы можете выполнить следующую команду установив свои настройки:
New-DedupSchedule -Type Unoptimization
Учитывайте, что вам потребуется больше свободного пространства для файлов (иначе дедупликация остановится с ошибкой) и процесс займет много ресурсов и времени. Копирование данных на другой том так же возможен и в этом случае файл тоже вернется в исходное состояние.
Мгновенный запуск дедупликации
Предыдущий пример, где мы устанавливали параметр Full, для проверки целостности всей базы, был не очень удачный. Дело в том, что мы можем устанавливать расписание только на неделю, а такая проверка рекомендуется раз в месяц. Для исправления этой ситуации мы можем использовать разовые задачи. Так я создам и запущу похожую задачу:
Аналогия команды
Например, запустите полную оптимизацию тома D с наивысшим приоритетом:
Start-DedupJob -Volume D: -Type Optimization -Memory 75 -Cores 100 -Priority High -FullНиже комманда что предлагаю в тесте
Start-DedupJob `
-Full `
-Volume 'E:' `
-Type 'Scrubbing'
Вернуть состояние задачи можно так:
Get-DedupJob

Если у вас есть настроенное расписание, то вы тоже его можете скопировать и запустить т.е. использовать как шаблон. Такая возможность явно не планировалась разработчиками и поэтому могут быть ошибки на этапе запуска. Например у меня была такие ошибки:
- Exception calling «EndProcessing» with «0» argument(s)
- Start-DedupJob : MSFT_DedupVolume.Volume=’
Одна из них была связана с отсутствием буквы раздела, так как я его не указал. Я дополнил параметры и все сработало корректно. Так же как и на примерах выше мы можем исправлять шаблон из планировщика как хотим. Ошибки могут быть разными, но они достаточно ясные и легко исправляются:
Get-DedupSchedule -Name 'полная проверка' | Start-DedupJob -InputOutputThrottleLevel Low -Volume 'E:'

Так же как и при создании запланированной задачи мы можем установить следующие параметры (более детально они описаны выше):
- Cores
- Full
- InputOutputThrottle
- InputOutputThrottleLevel
- Memory
- Priority
- ReadOnly
- StopWhenSystemBusy
- ThrottleLimit
- Type
А эти параметры есть только у Start-DedupSchedule:
- Preempt — форсированный запуск задачи, отменяющий иные;
- Timestamp — работает только с задачами типа ‘Unoptimization’ и принимает значения типа данных DateTime. Отменяет оптимизацию файлов оптимизированных с указанной даты;
- Volume — можно указать один или несколько томов. Можно указывать буквы формата ‘E:’, ID и GUID;
- Wait — в фоне будет отображаться процесс задачи и ее результат. Пример ниже.

Пример отмены задач:
Get-DedupJob -Type Scrubbing | Stop-DedupJob # или Stop-DedupJob -Volume 'E:','C:'
Отмену дедупликации вы так же можете запустить задачей:
Start-DedupJob -Volume D: -Type Unoptimization -Memory 100 -Cores 100 -Priority High -Full
Статус дедупликации
Следующая команда вернет текущий статус дедупликации:
# Сокращенный вариант
Get-DedupStatus
# Полный отчет
Get-DedupStatus | select *
Предыдущая команда возвращает закэшированные данные, но если вы хотите получить наиболее актуальную информацию вы можете выполнить следующую команду:
# Для всех томов
Update-DedupStatus
# Для одного тома
Update-DedupStatus -Volume 'E:'
# Возвращение полной актуальной информации по тому
Update-DedupStatus -Volume 'E:' | SELECT *
Следующая команда вернет время последнего выполнения каждого из процессов дедупликации:
Get-DedupStatus -Volume 'E:' | select -Property "time" | fl

Эта команда вернет информацию по работе с файлами:
Get-DedupStatus -Volume 'E:' | select -Property "file",'srate' | fl

Где:
- InPolicyFilesCount — количество файлов, которые подходят для оптимизации;
- InPolicyFilesSize — общий размер файлов, которые подходят для оптимизации;
- OptimizedFilesCount — количество файлов, которые были оптимизированы;
- OptimizedFilesSavingRate — процент оптимизированных файлов относительно всех файлов которые подходят под установленные параметры;
- OptimizedFilesSize — общий размер оптимизированных файлов.
Более точно эти данные отображаются после процесса сборки мусора и оптимизации.
Следующая команда вернет данные из базы дедупликации по определенному тому:
Get-DedupMetadata -Volume 'E:'

Если такой запрос завершится ошибкой, то скорее всего, в данный момент, происходит один из процессов дедупликации, который меняет эти метаданные.
По выводу мы можем увидеть:
- DataChunkCount — количество чанков, размером 32-128 Кб на одном томе;
- DataContainerCount — количество контейнеров;
- DataChunkAverageSize — средний размер одного чанка (размер контейнера поделенный на количество чанков);
- TotalChunkStoreSize — размер хранилища;
- CorruptionLogEntryCount — количество ошибок на томе.
Свойства типа «Stream*» скорее всего показывают данные по открытым файлам или проходящие через Volume Shadow Copy.
Если будет необходимость в освобождения места (переносом или удалением) подсчет потенциально освобождающегося пространства будет сложной задачей. Связано это с тем, что не ясно количество дедуплицированных файлов (они могут быть в трех, четырех копиях, в разных местах и т.д.). В этом случае можно использовать команду Measure-DedupFileMetadata:
Measure-DedupFileMetadata -Path 'E:New folder'

Где:
- FilesCount — количество файлов на всем томе;
- OptimizedFilesCount — количество оптимизированных файлов на всем томе;
- Size — суммарный размер всех файлов;
- DedupSize — итоговый размер дедуплицированных файлов в этой папке;
Восстановление дедуплицированных файлов
Команда Expand-DedupFile восстанавливает файл, который был оптимизирован в его исходное место. Такая операция может понадобится, когда стороннее приложение (например программы бэкапа) не могут корректно работать с файлом. Важным моментом восстановления таких файлов является достаточное количество места на диске. Следующим образом я восстановлю два файла в их исходное местоположение:
Expand-DedupFile -Path 'E:New folderOtchet2020.doc','E:New folder3285.wav'
Никакого вывода команда не выдает, но если файл не был дедуплицирован, то вы получите ошибку:
Expand-DedupFile : MSFT_DedupVolume.Path='E:file1' - HRESULT 0x80070057, The parameter is incorrect.
При ошибке целого тома
PS C:Windowssystem32> Expand-DedupFile -Path F:
Expand-DedupFile : MSFT_DedupVolume.Path='F:' - HRESULT 0x80070005, Access is denied.
At line:1 char:2
+ Expand-DedupFile -Path F:Можно выполнить команду которая рекурсивно пройдет по всему тому и восстановит дедуплицированные файлыGet-ChildItem F: -Recurse -Attributes !D | Expand-DedupFile

После выполнения данной команды , доступ к файлам через проводник зависнет на самом сервере, но для других файлы будут доступны!!!
Процент данных , также будет уменьшатся

После делаем командуUpdate-DedupStatus
Отключение Deduplication
На томе отключаем дедупликацию

Восстанавливаем файлыGet-ChildItem F: -Recurse -Attributes !D | Expand-DedupFile
Обновляем статус
Update-DedupStatus
Где найти логи Deduplication
Applications and services — logsMicrosoftWindowsDedupliation
Восстановление данных с HDD после дедупликации Windows Server
К примеру, если вышла из строя система Windows Server в которой, выполнялась дедупликация одного из жестких дисков. Возможно, ли подключить этот диск к другому компьютеру и считать , восстановить эти данные?
Вся информация о дедупликации хранится на самом диске. Поэтому будет достаточно подключить диск/диски к другому ПК/Серверу с Windows Server , включить на нём дедупликацию и получить доступ к вашему старому диску.
Дедуплицированные папки весят 0 байт
Это означаем что по указанному пути файлы дедуплицированы
Дудуплицированные файлы весят 0 байт
Восстановите файл из бэкапа
Storage technologies have certainly evolved over the past several years and provide many powerful tools to allow the most efficient use of provisioned space. One of the technologies available in Windows Server is deduplication. Microsoft continues to add new capabilities to the deduplication feature with each Windows release.
Contents
- What is data deduplication in Windows Server?
- How does Windows Server data deduplication work?
- Strong use cases for data deduplication
- Installing the Windows Server Dedup
- Enabling Data Deduplication on a Windows Server volume
- Running Data Deduplication Scheduled Tasks
- Using PowerShell for status and management
- Wrapping up
- Author
- Recent Posts

Brandon Lee has been in the IT industry 15+ years and focuses on networking and virtualization. He contributes to the community through various blog posts and technical documentation primarily at Virtualizationhowto.com.
What benefits are provided by Windows Server deduplication? How is the feature added? How do you enable deduplication, check its status, and pause or stop the deduplication process? Let’s take a look at Windows Server deduplication.
What is data deduplication in Windows Server?
When you store data comprising various files and other data on any Windows Server, there will be duplicated data blocks among the multiple files. It is especially true if the different files stored on a Windows Server volume are similar in content or structure. A departmental file server is a good example that helps visualize how there may be vast amounts of duplicated data. In a large file share, end users may store many copies of the same or similar files. This leads to redundant copies of data that impact the efficiency of storage.
Instead of storing multiple copies of data, as in traditional storage environments, deduplication provides the means to store the data once and create intelligent pointers to the actual data location. In this way, the storage environment does not house duplicated information. Microsoft keeps improving the features of deduplication as well. In Windows Server 2019, Data Deduplication can now deduplicate both NTFS and ReFS volumes. Prior to Windows Server 2019, ReFS deduplication was not possible.
How does Windows Server data deduplication work?
Microsoft uses two principles to implement data deduplication in Windows Server:
- The deduplication process runs on data by using a post-processing model. This means that the deduplication process does not interfere with the performance of the write process. When data is written to the storage, it is not optimized. Afterward, the deduplication optimization process runs to ensure the deduplication of the data.
- End users are unaware of the deduplication process—Deduplication in Windows Server is entirely transparent. End users are unaware they may be working with deduplicated data.
To accomplish the successful deduplication of data in accordance with the principles listed above, Windows Server uses the following process:
- The file system scans storage to find files matching the deduplication optimization policy.
- The system breaks the files into chunks.
- Unique chunks of file data are identified.
- These file chunks are placed in the chunk store.
- Pointers to the chunk store are created to allow redirecting file reads to the appropriate file chunks.
Strong use cases for data deduplication
Specific use cases lend themselves favorable to data deduplication. What are workloads that typically show massive benefits to using data deduplication? Let’s list these in the order of the most significant benefits.
- 80–95% space savings—Virtualization environments, especially VDI workloads and ISOs for deployment.
- 70–80% space savings—Deployment shares contain massively duplicated data stores of software binaries, cab files, and other operation-specific files.
- 50–60% space savings—General file shares can contain monolithic repositories of files that can include a tremendous amount of duplicated data.
- 30–50% space savings—User documents can contain standard user files that may include photos, music, and videos.
Installing the Windows Server Dedup
The process to install the Windows Server Dedup feature is straightforward. Administrators can install Dedup using the GUI Server Manager, Windows Admin Center, or PowerShell. Data Deduplication is part of the File and Storage Services role in Windows Server. Below is a screenshot from Windows Server 2019.

Installing the Data Deduplication File and Storage Services role in Windows Server 2019
Using PowerShell, you can enable data deduplication using the following cmdlet:
Install-WindowsFeature -Name FS-Data-Deduplication
Data Deduplication installation in Windows Admin Center is carried out by visiting the Roles and Features menu and placing a check next to Data Deduplication, which is found under the File and Storage Services role.

Using Windows Admin Center to install Data Deduplication in Windows Server 2019
Enabling Data Deduplication on a Windows Server volume
Once you have installed Data Deduplication, the process to enable it on a volume is straightforward. Using Server Manager, navigate to File and Storage Services > Volumes > Disks. Click the disk. Then click the volume that resides on the disk that you want to deduplicate.

Enabling Data Deduplication for a Windows Server 2019 volume
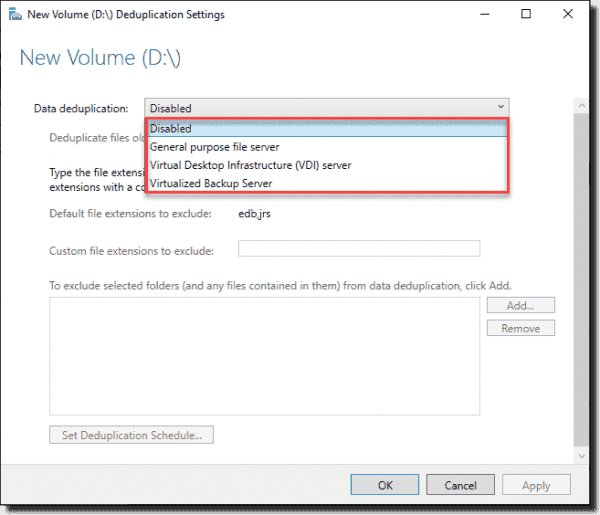
Choose the type of files stored on the volume to be deduplicated
Under Deduplication Settings, you can configure several options. These include:
- The age of the files to be deduplicated
- Custom file extensions to exclude
- Custom excluded folders
- Configuration of the deduplication schedule

Configuring Windows Server deduplication setting
The Deduplication Schedule configuration provides interesting options to customize the background process used to run the data deduplication. You can further customize the deduplication schedule and resource utilization using the throughput optimization options. It also allows for multiple schedules.

Setting the deduplication schedule in Windows Server 2019
Running Data Deduplication Scheduled Tasks
You may wonder how the background tasks run. When you install Data Deduplication, Windows creates scheduled tasks to take care of the background process, garbage collection, and data scrubbing. If you want to run these manually, you can. The background deduplication process runs by default every 1 hour indefinitely.

Windows Deduplication Scheduled Tasks in Windows Server 2019
Using PowerShell for status and management
PowerShell provides many great controls and options for interacting with Windows Server Data Deduplication. Let’s take note of a few of these cmdlets. The Get-DedupStatus cmdlet displays the status of the deduplication operations and the deduplication percentage.
As you can see, at first, we have no space savings after Data Deduplication is installed and enabled. However, after the process begins to run, we start to see space savings on the volume.

Getting the status of Data Deduplication for a storage volume in Windows Server
If you want to disable and get rid of Data Deduplication, you can do this easily with a couple of PowerShell cmdlets:
Disable-DedupVolume -Volume <volume letter> Start-DedupJob -type Unoptimization -Volume <volume letter>
What other types of DedupJobs can you kick off from PowerShell?
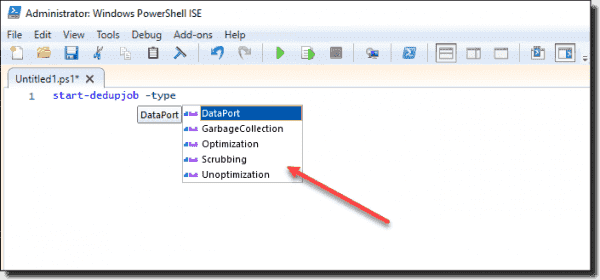
Looking at the start dedupjob cmdlet type options in Windows Server 2019
Wrapping up
Windows Server Data Deduplication is a great way to reclaim storage space efficiently in your Windows Server environment. With each Windows release, the deduplication capabilities continue to improve. It provides tremendous space-saving benefits with specific workloads, especially for general file servers and VDI virtualization environments. For virtualization environments, space savings can be as much as 80–95%.
Subscribe to 4sysops newsletter!
The Data Deduplication subcomponent of File and Storage Services is easy to add and enable on a specific storage volume. You can take advantage of many options to control the deduplication schedule, file types, and exclusions. PowerShell provides several cmdlets that allow interacting with, managing, and controlling Windows Server Data Deduplication.
![]()
I was recently asked to help out our friends at Channel 9 with a storage problem. They capture large video files as part of their recordings and have to have them local for fast access in order to edit them. They currently use a proprietary Linux box for NFS storage which is just about full. I have spec’ed out a Storage Spaces Direct setup on Windows 2019 from the Azure Stack HCI catalog – but it won’t be in for a while. This is the first bare metal system I’ve had to rack and stack in a while and it’s part of a longer project – so I thought it would be good to write up a short set of topical blog posts to go along with the process.
Finding the right physical server from on-premises inventory
First off – I am spoiled by running a simple Azure command to provision whatever size box I need in a matter of minutes – this is going back in time for me. Luckily, I have an old DataOn Cluster-in-a-box system from a lab that has some decent (70 TB) worth of storage to temporarily hold them over until the new system arrives.

Like a fresh coat of paint – flattening and rebuilding the servers from a USB media was kind of refreshing. In no time at all I have two nodes of a Windows Server 2019 up and running.
Installing Data Deduplication
The files they are storing includes large video files copied up to the system by various camera operators in the field. There isn’t a sophisticated logging system on what file came where or if files have already been dumped up on the share. As a result – we’ve got duplicates. I figured one easy way of resolving this space issue is to enable deduplication. Data Deduplication in Windows Server 2019 is more efficient than previous releases – it can run in the background on multiple volumes with minimal impact on other workloads. If you want some more details on Deduplication – we’ve got a good article over on Microsoft Docs you should check out.
The temporary server in question has the fresh install of Windows Server 2019 with all available drives configured in a storage pool with a single volume. I really just needed to get this thing up, enable deduplication and copy over the data from the Linux box until the new AzureStack HCI configuration comes in.
The fastest way to install the DataDeduplication feature is to crack open a PowerShell window and type in Add-WindowsFeature -name FS-Data-Deduplication

Enabling and Configuring Data Deduplication on Data Drive
To enable the default settings for DataDeduplication for my E: drive- it’s was simple as typing in Enable-DedupVolume E:

Because this is a temporary server – I want to configure the minimum file age to be “0” in order for the server to start deduplicating files on the next job schedule or manual kickoff. To change this parameter – type in Set-DedupVolume -Volume “E:” -MinimumFileAgeDays 0
Time to Finish Rack and Stack / Install
At this point we’re all ready to go. It’s a matter of transporting and installing this box into it’s temporary home and transferring the files over to it from the Linux NAS box. But for this – you’ll have to wait until the next post in this short series.
From start to finish – this took the better part of an afternoon to provision some bare metal, with 70 TB of storage as a temporary server. That is a tad longer then what seems like a very long 5 minutes to provision a system in Azure – but the proximity and fast access to these source files is what is important to the team at Channel 9.
All this being said – as I was going through this – I was thinking of all the value-add services from Azure I could bring to this on-prem bare metal box. Once the more permanent solution is in place – I’ll go through the process of adding on a few of these Azure services to help me out: Azure File Sync, Azure Backup and a bunch of the Management add-ons to monitor the health of the system and so on.
What about you? Have you considered or started to explore any of the Hybrid Azure-to-on-prem services?
При дедупликации [https://docs.microsoft.com/ru-ru/windows-server/storage/data-deduplication/understand#how-does-dedup-work, https://docs.microsoft.com/ru-ru/windows-server/storage/data-deduplication/overview] на диске остаётся один набор данных, а повторяющиеся части заменяются указателями (ссылками) на оригинал при этом не нарушается достоверность или целостность и появляется дополнительное пространство.
В качестве минусов можно отметить, что не рекомендуется использовать данный тип экономии для системных дисков, существует риск потери данных, в теории может замедлить работу сервера.
К плюсам дедупликации отнесём поддержку ReFS, больших объёмов файлов (до 1 Тб) и томов (до 64 Тб), наличие самодиагностики (поиск битых блоков), работу с .vhdx-файлами и даже с живыми виртуальными машинами, последовательное обновление кластерной ОС, будет тратиться меньше времени на резервное копирование или репликацию, простота настройки.
Размер освобождаемого места зависит от типов файлов, а именно:
· фотографии, музыка, видео – 30-35%;
· офисные документы – 50-60%;
· двоичные файлы программ, CAB-файлы, символы – 70-80%;
· образы ISO, файлы виртуальных жестких дисков – 80-95%;
· все вышеперечисленное – 50-60%.
У дедупликации имеются несколько сценариев применения:
1. для файловых серверов, которые содержат групповые общие папки, домашние и рабочие папки пользователей, общие ресурсы для разработки ПО (наш случай);
2. для виртуальных рабочих столов (VDI), так как виртуальные жёсткие диски тут, по сути, идентичны;
3. для бэкапов хранилищ, так как значительная часть снэпшотов дублируется.
Чтобы включить дедупликацию, нужно зайти в список ролей, найти Файловые службы и службы хранилища->Файловые службы и службы iSCSI и активировать Дедупликация данных (можно и с помощью PowerShell или консоли Windows Admin Center). После установки роли в C:Windowssystem32 появится утилита ddpeval.exe, которая позволяет определить надобность в дедупликации. Запустив её в командной строке (в cmd) ddpeval.exe d:, станет видно, сколько можно освободить места.
Теперь в графической консоли Диспетчер серверов заходим в Файловые службы и службы хранилища, находим пункт Тома, у нас будет задействован том D:. В контекстном меню выбираем пункт Настройка дедупликации данных (см. рис. 1).

Рисунок 1. Настройка дедупликации.
В появившемся окне в выпадающем списке будет 3 варианта: Файловый сервер общего назначения, Сервер инфраструктуры виртуальных рабочих столов (VDI), Виртуализированный резервный сервер. Мы выбираем первый пункт.
Затем (при желании) указывается возраст файлов, типы файлов и папки, которые будут исключены из дедупликации, и выбирается расписание. После этого в графической консоли Планировщик заданий появится ветка Deduplication с расписанием фоновых заданий. Средняя скорость дедупликации в Windows Server 2019 составляет 25 Мб/с, а это приблизительно 87 ГБ/час.
Далее применим некоторые командлеты PowerShell. Например, с помощью Get-DedupVolume -Volume D: | fl увидим объём диска, свободное место на нём, объем оптимизирующего пространства, а также исключённые по умолчанию типы файлов (avi, edb, jrs, asf, mov, wma, wmv), обратив внимание на значение параметра SavingsRate — сейчас показывает 0%, что означает отсутствие дедупликации (см. рис. 2).

Рисунок 2. Проверка для дедупликации.
Если нужно запустить дедупликацию сейчас, то можно это сделать в ручном режиме с помощью командлета Start-DedupJob -Type Optimization -Volume D: -Memory 100 -Cores 100 -Priority High, причём процесс выполнится с максимальной загрузкой процессора и памяти, здесь же можно наблюдать за его выполнением в реальном времени в процентах.
После этого снова запускаем Get-DedupVolume -Volume D: | fl и видим, что параметр SavingsRate = 22%, и это равно 554 Мб сэкономленного места (параметр SavingSpace).
В процессе оптимизации места в системной папке System Volume Information создаётся папка Dedup, в которой и хранятся ссылочные данные (метаданные). Содержимое этой папки можно просмотреть командой vssadmin List ShadowStorage.
When Windows Server 2016 was released, Data Deduplication was not available for ReFS file system, and only available for NTFS. With Windows Server 2019, data deduplication is now available for both NTFS and ReFS file systems.
Data Deduplication is a great technology that allows you to reduces your storage footprint by removing any duplicated data blocks and replacing it with metadata.
In the scenario below, I will show you how to enable Data Deduplication and tracking the ‘saving rate’ of the data deduplication.
Install-WindowsFeature FS-Data-Deduplication

This cmdlet will allow you to install the feature. In most scenarios, ie. Storage Spaces Direct, Hyper-V, this will make most sense. Also, this cmdlet would need to be executed on all nodes.
Get-Command *Dedup*

Now that we have data deduplication installed, we can now see all the of the cmdlets available.
Enable-DedupVolume -Volume "E:","F:" -UsageType HyperV
Finally, once we enable data deduplication on the volumes, we can now track the saving rate. Note, this can be done via PowerShell, or Windows Admin Center (WAC). Note, this can only be enabled on Cluster Shared Volumes (CSV).
Get-DedupVolume
I hope this helps, and now you can start minimizing the data deduplication within your environment.
Hey Checkyourlogs Fans,
In today’s post, we will look at the steps required to enable deduplication in Windows Server 2019 on a ReFS volume. What I have done to get started is installed a Virtual Machine running Windows Server 2019 Insiders Build.

Next, we need to install the deduplication feature as seen in the image below.

Once installed you can use Server Manager to configure it on your Volume. In this example, I have added an E: drive and formatted it using ReFS.

To enable deduplication on the ReFS volume you simply need to right-click on the volume and click Configure Data Deduplication.

This will open the Deduplication Settings page and now we just need to make a few configurations and we are done.
For this use case, I am planning on using the volume for my Hyper-V Lab Virtual Machines.
I have changed the Data deduplication setting to Virtual Desktop Infrastructure (VDI) Server and Deduplication files older than (in days): 0.

The last step is to configure the schedule and we are done. Click on the Set Deduplication Schedule button.

In my lab,, I always choose all three options and leave the default schedule. It is really important to note that just like Deduplication on an NTFS volume this is all done post-process. Meaning that you have to wait for the scheduled tasks to run for the Deduplication engine to start working.


We can check the status using PowerShell which I will cover in the next blog post. For now, I will leave you with how to manually kick off using the build in scheduled tasks.

I really hope you enjoyed this post and stay tuned for a lot more on Deduplication on ReFS.
Thanks,
Dave