Windows by Zabbix agent active
Overview
New official Windows template. Requires agent of Zabbix 4.4 and newer.
This template has been tested on:
- Windows, version 7 and newer.
- Windows Server, version 2008 R2 and newer.
Requirements
For Zabbix version: 6.4 and higher.
Setup
Install Zabbix agent on Windows OS according to Zabbix documentation.
Configuration
No specific Zabbix configuration is required.
Macros used
| Name | Description | Default |
|---|---|---|
| {$AGENT.NODATA_TIMEOUT} |
No data timeout for active agents. Consider to keep it relatively high. |
30m |
| {$AGENT.TIMEOUT} |
Timeout after which agent is considered unavailable. |
5m |
| {$CPU.INTERRUPT.CRIT.MAX} |
The critical threshold of the % Interrupt Time counter. |
50 |
| {$CPU.PRIV.CRIT.MAX} |
The threshold of the % Privileged Time counter. |
30 |
| {$CPU.QUEUE.CRIT.MAX} |
The threshold of the Processor Queue Length counter. |
3 |
| {$CPU.UTIL.CRIT} |
The critical threshold of the CPU utilization in %. |
90 |
| {$IF.ERRORS.WARN} |
— |
2 |
| {$IF.UTIL.MAX} |
— |
90 |
| {$IFCONTROL} |
— |
1 |
| {$MEM.PAGE_SEC.CRIT.MAX} |
The warning threshold of the Memory Pages/sec counter. |
1000 |
| {$MEM.PAGE_TABLE_CRIT.MIN} |
The warning threshold of the Free System Page Table Entries counter. |
5000 |
| {$MEMORY.UTIL.MAX} |
The warning threshold of the Memory util item. |
90 |
| {$NET.IF.IFALIAS.MATCHES} |
This macro is used in Network interface discovery. Can be overridden on the host or linked template level. |
.* |
| {$NET.IF.IFALIAS.NOT_MATCHES} |
This macro is used in Network interface discovery. Can be overridden on the host or linked template level. |
CHANGE_THIS |
| {$NET.IF.IFDESCR.MATCHES} |
This macro is used in Network interface discovery. Can be overridden on the host or linked template level. |
.* |
| {$NET.IF.IFDESCR.NOT_MATCHES} |
This macro is used in Network interface discovery. Can be overridden on the host or linked template level. |
CHANGE_THIS |
| {$NET.IF.IFNAME.MATCHES} |
This macro is used in Network interface discovery. Can be overridden on the host or linked template level. |
.* |
| {$NET.IF.IFNAME.NOT_MATCHES} |
This macro is used in Network interface discovery. Can be overridden on the host or linked template level. |
`Miniport |
| {$SERVICE.NAME.MATCHES} |
This macro is used in Service discovery. Can be overridden on the host or linked template level. |
^.*$ |
| {$SERVICE.NAME.NOT_MATCHES} |
This macro is used in Service discovery. Can be overridden on the host or linked template level. |
`^(?:RemoteRegistry |
| {$SERVICE.STARTUPNAME.MATCHES} |
This macro is used in Service discovery. Can be overridden on the host or linked template level. |
`^(?:automatic |
| {$SERVICE.STARTUPNAME.NOT_MATCHES} |
This macro is used in Service discovery. Can be overridden on the host or linked template level. |
`^(?:manual |
| {$SWAP.PFREE.MIN.WARN} |
The warning threshold of the minimum free swap. |
20 |
| {$SYSTEM.FUZZYTIME.MAX} |
The threshold for difference of system time in seconds. |
60 |
| {$VFS.DEV.DEVNAME.MATCHES} |
This macro is used in physical disks discovery. Can be overridden on the host or linked template level. |
.* |
| {$VFS.DEV.DEVNAME.NOT_MATCHES} |
This macro is used in physical disks discovery. Can be overridden on the host or linked template level. |
_Total |
| {$VFS.DEV.READ.AWAIT.WARN} |
Disk read average response time (in s) before the trigger would fire. |
0.02 |
| {$VFS.DEV.UTIL.MAX.WARN} |
The warning threshold of disk time utilization in percent. |
95 |
| {$VFS.DEV.WRITE.AWAIT.WARN} |
Disk write average response time (in s) before the trigger would fire. |
0.02 |
| {$VFS.FS.FREE.MIN.CRIT} |
The critical threshold of the filesystem utilization. |
5G |
| {$VFS.FS.FREE.MIN.WARN} |
The warning threshold of the filesystem utilization. |
10G |
| {$VFS.FS.FSDRIVETYPE.MATCHES} |
This macro is used in filesystems discovery. Can be overridden on the host or linked template level. |
fixed |
| {$VFS.FS.FSDRIVETYPE.NOT_MATCHES} |
This macro is used in filesystems discovery. Can be overridden on the host or linked template level. |
^s$ |
| {$VFS.FS.FSNAME.MATCHES} |
This macro is used in filesystems discovery. Can be overridden on the host or linked template level. |
.* |
| {$VFS.FS.FSNAME.NOT_MATCHES} |
This macro is used in filesystems discovery. Can be overridden on the host or linked template level. |
`^(?:/dev |
| {$VFS.FS.FSTYPE.MATCHES} |
This macro is used in filesystems discovery. Can be overridden on the host or linked template level. |
.* |
| {$VFS.FS.FSTYPE.NOT_MATCHES} |
This macro is used in filesystems discovery. Can be overridden on the host or linked template level. |
^s$ |
| {$VFS.FS.PUSED.MAX.CRIT} |
The critical threshold of the filesystem utilization in percent. |
90 |
| {$VFS.FS.PUSED.MAX.WARN} |
The warning threshold of the filesystem utilization in percent. |
80 |
Template links
There are no template links in this template.
Discovery rules
| Name | Description | Type | Key and additional info |
|---|---|---|---|
| Mounted filesystem discovery |
Discovery of file systems of different types. |
DEPENDENT | vfs.fs.dependent.discovery
Filter: AND — {#FSTYPE} MATCHES_REGEX — {#FSTYPE} NOT_MATCHES_REGEX — {#FSNAME} MATCHES_REGEX — {#FSNAME} NOT_MATCHES_REGEX — {#FSDRIVETYPE} MATCHES_REGEX — {#FSDRIVETYPE} NOT_MATCHES_REGEX |
| Network interfaces discovery |
Discovery of installed network interfaces. |
DEPENDENT | net.if.discovery
Preprocessing: — JAVASCRIPT: — DISCARD_UNCHANGED_HEARTBEAT: Filter: AND — {#IFNAME} MATCHES_REGEX — {#IFNAME} NOT_MATCHES_REGEX — {#IFDESCR} MATCHES_REGEX — {#IFDESCR} NOT_MATCHES_REGEX — {#IFALIAS} MATCHES_REGEX — {#IFALIAS} NOT_MATCHES_REGEX |
| Physical disks discovery |
Discovery of installed physical disks. |
ZABBIX_ACTIVE | perf_instance_en.discovery[PhysicalDisk]
Preprocessing: — STR_REPLACE: Filter: AND — {#DEVNAME} MATCHES_REGEX — {#DEVNAME} NOT_MATCHES_REGEX |
| Windows services discovery |
Discovery of Windows services of different types as defined in template’s macros. |
ZABBIX_ACTIVE | service.discovery
Filter: AND — {#SERVICE.NAME} MATCHES_REGEX — {#SERVICE.NAME} NOT_MATCHES_REGEX — {#SERVICE.STARTUPNAME} MATCHES_REGEX — {#SERVICE.STARTUPNAME} NOT_MATCHES_REGEX |
Items collected
| Group | Name | Description | Type | Key and additional info |
|---|---|---|---|---|
| CPU | CPU utilization |
The CPU utilization expressed in %. |
ZABBIX_ACTIVE | system.cpu.util |
| CPU | CPU interrupt time |
The Processor Information% Interrupt Time is the time the processor spends receiving and servicing hardware interrupts during sample intervals. This value is an indirect indicator of the activity of devices that generate interrupts, such as the system clock, the mouse, disk drivers, data communication lines, network interface cards and other peripheral devices. This is an easy way to identify a potential hardware failure. This should never be higher than 20%. |
ZABBIX_ACTIVE | perf_counter_en[«Processor Information(_total)% Interrupt Time»] |
| CPU | Context switches per second |
Context Switches/sec is the combined rate at which all processors on the computer are switched from one thread to another. Context switches occur when a running thread voluntarily relinquishes the processor, is preempted by a higher priority ready thread, or switches between user-mode and privileged (kernel) mode to use an Executive or subsystem service. It is the sum of ThreadContext Switches/sec for all threads running on all processors in the computer and is measured in numbers of switches. There are context switch counters on the System and Thread objects. This counter displays the difference between the values observed in the last two samples, divided by the duration of the sample interval. |
ZABBIX_ACTIVE | perf_counter_en[«SystemContext Switches/sec»] |
| CPU | CPU privileged time |
The Processor Information% Privileged Time counter shows the percent of time that the processor is spent executing in Kernel (or Privileged) mode. Privileged mode includes services interrupts inside Interrupt Service Routines (ISRs), executing Deferred Procedure Calls (DPCs), Device Driver calls and other kernel-mode functions of the Windows® Operating System. |
ZABBIX_ACTIVE | perf_counter_en[«Processor Information(_total)% Privileged Time»] |
| CPU | CPU DPC time |
Processor DPC time is the time that a single processor spent receiving and servicing deferred procedure calls (DPCs). DPCs are interrupts that run at a lower priority than standard interrupts. % DPC Time is a component of % Privileged Time because DPCs are executed in privileged mode. If a high % DPC Time is sustained, there may be a processor bottleneck or an application or hardware related issue that can significantly diminish overall system performance. |
ZABBIX_ACTIVE | perf_counter_en[«Processor Information(_total)% DPC Time»] |
| CPU | CPU user time |
The Processor Information% User Time counter shows the percent of time that the processor(s) is spent executing in User mode. |
ZABBIX_ACTIVE | perf_counter_en[«Processor Information(_total)% User Time»] |
| CPU | Number of cores |
The number of logical processors available on the computer. |
ZABBIX_ACTIVE | wmi.get[root/cimv2,»Select NumberOfLogicalProcessors from Win32_ComputerSystem»] |
| CPU | CPU queue length |
The Processor Queue Length shows the number of threads that are observed as delayed in the processor Ready Queue and are waiting to be executed. |
ZABBIX_ACTIVE | perf_counter_en[«SystemProcessor Queue Length»] |
| Filesystems | {#FSLABEL}({#FSNAME}): Used space |
Used storage expressed in Bytes. |
DEPENDENT | vfs.fs.dependent.size[{#FSNAME},used]
Preprocessing: — JSONPATH: |
| Filesystems | {#FSLABEL}({#FSNAME}): Total space |
The total space expressed in Bytes. |
DEPENDENT | vfs.fs.dependent.size[{#FSNAME},total]
Preprocessing: — JSONPATH: |
| Filesystems | {#FSLABEL}({#FSNAME}): Space utilization |
Space utilization in % for {#FSNAME} |
DEPENDENT | vfs.fs.dependent.size[{#FSNAME},pused]
Preprocessing: — JSONPATH: |
| General | System local time |
The local system time of the host. |
ZABBIX_ACTIVE | system.localtime |
| General | System name |
The host name of the system. |
ZABBIX_ACTIVE | system.hostname
Preprocessing: — DISCARD_UNCHANGED_HEARTBEAT: |
| General | System description |
System description of the host. |
ZABBIX_ACTIVE | system.uname
Preprocessing: — DISCARD_UNCHANGED_HEARTBEAT: |
| General | Number of processes |
The number of processes. |
ZABBIX_ACTIVE | proc.num[] |
| General | Number of threads |
The number of threads used by all running processes. |
ZABBIX_ACTIVE | perf_counter_en[«SystemThreads»] |
| Inventory | Operating system |
— |
ZABBIX_ACTIVE | system.sw.os
Preprocessing: — DISCARD_UNCHANGED_HEARTBEAT: |
| Inventory | Operating system architecture |
The architecture of the operating system. |
ZABBIX_ACTIVE | system.sw.arch
Preprocessing: — DISCARD_UNCHANGED_HEARTBEAT: |
| Memory | Used memory |
Used memory in Bytes. |
ZABBIX_ACTIVE | vm.memory.size[used] |
| Memory | Total memory |
The total memory expressed in Bytes. |
ZABBIX_ACTIVE | vm.memory.size[total] |
| Memory | Memory utilization |
Memory utilization in %. |
CALCULATED | vm.memory.util
Expression:
|
| Memory | Cache bytes |
Cache Bytes is the sum of the MemorySystem Cache Resident Bytes, MemorySystem Driver Resident Bytes, MemorySystem Code Resident Bytes, and MemoryPool Paged Resident Bytes counters. This counter displays the last observed value only; it is not an average. |
ZABBIX_ACTIVE | perf_counter_en[«MemoryCache Bytes»] |
| Memory | Free swap space |
The free space of the swap volume/file expressed in bytes. |
CALCULATED | system.swap.free
Expression:
|
| Memory | Free swap space in % |
The free space of the swap volume/file expressed in %. |
DEPENDENT | system.swap.pfree
Preprocessing: — JAVASCRIPT: |
| Memory | Used swap space in % |
The used space of swap volume/file in percent. |
ZABBIX_ACTIVE | perf_counter_en[«Paging file(_Total)% Usage»] |
| Memory | Total swap space |
The total space of the swap volume/file expressed in bytes. |
ZABBIX_ACTIVE | system.swap.size[,total] |
| Memory | Free system page table entries |
This indicates the number of page table entries not currently in use by the system. If the number is less than 5,000, there may well be a memory leak or you running out of memory. |
ZABBIX_ACTIVE | perf_counter_en[«MemoryFree System Page Table Entries»] |
| Memory | Memory page faults per second |
Page Faults/sec is the average number of pages faulted per second. It is measured in number of pages faulted per second because only one page is faulted in each fault operation, hence this is also equal to the number of page fault operations. This counter includes both hard faults (those that require disk access) and soft faults (where the faulted page is found elsewhere in physical memory.) Most processors can handle large numbers of soft faults without significant consequence. However, hard faults, which require disk access, can cause significant delays. |
ZABBIX_ACTIVE | perf_counter_en[«MemoryPage Faults/sec»] |
| Memory | Memory pages per second |
This measures the rate at which pages are read from or written to disk to resolve hard page faults. If the value is greater than 1,000, as a result of excessive paging, there may be a memory leak. |
ZABBIX_ACTIVE | perf_counter_en[«MemoryPages/sec»] |
| Memory | Memory pool non-paged |
This measures the size, in bytes, of the non-paged pool. This is an area of system memory for objects that cannot be written to disk but instead must remain in physical memory as long as they are allocated. There is a possible memory leak if the value is greater than 175MB (or 100MB with the /3GB switch). A typical Event ID 2019 is recorded in the system event log. |
ZABBIX_ACTIVE | perf_counter_en[«MemoryPool Nonpaged Bytes»] |
| Monitoring agent | Version of Zabbix agent running |
— |
ZABBIX_ACTIVE | agent.version
Preprocessing: — DISCARD_UNCHANGED_HEARTBEAT: |
| Monitoring agent | Host name of Zabbix agent running |
— |
ZABBIX_ACTIVE | agent.hostname
Preprocessing: — DISCARD_UNCHANGED_HEARTBEAT: |
| Monitoring agent | Active agent availability |
Availability of active checks on the host. The value of this item corresponds to availability icons in the host list. Possible value: 0 — unknown 1 — available 2 — not available |
INTERNAL | zabbix[host,active_agent,available] |
| Network interfaces | Interface {#IFNAME}({#IFALIAS}): Bits received |
Incoming traffic on the network interface. |
ZABBIX_ACTIVE | net.if.in[«{#IFGUID}»]
Preprocessing: — CHANGE_PER_SECOND — MULTIPLIER: |
| Network interfaces | Interface {#IFNAME}({#IFALIAS}): Bits sent |
Outgoing traffic on the network interface. |
ZABBIX_ACTIVE | net.if.out[«{#IFGUID}»]
Preprocessing: — CHANGE_PER_SECOND — MULTIPLIER: |
| Network interfaces | Interface {#IFNAME}({#IFALIAS}): Inbound packets discarded |
The number of incoming packets dropped on the network interface. |
ZABBIX_ACTIVE | net.if.in[«{#IFGUID}»,dropped]
Preprocessing: — CHANGE_PER_SECOND |
| Network interfaces | Interface {#IFNAME}({#IFALIAS}): Outbound packets discarded |
The number of outgoing packets dropped on the network interface. |
ZABBIX_ACTIVE | net.if.out[«{#IFGUID}»,dropped]
Preprocessing: — CHANGE_PER_SECOND |
| Network interfaces | Interface {#IFNAME}({#IFALIAS}): Inbound packets with errors |
The number of incoming packets with errors on the network interface. |
ZABBIX_ACTIVE | net.if.in[«{#IFGUID}»,errors]
Preprocessing: — CHANGE_PER_SECOND |
| Network interfaces | Interface {#IFNAME}({#IFALIAS}): Outbound packets with errors |
The number of outgoing packets with errors on the network interface. |
ZABBIX_ACTIVE | net.if.out[«{#IFGUID}»,errors]
Preprocessing: — CHANGE_PER_SECOND |
| Network interfaces | Interface {#IFNAME}({#IFALIAS}): Speed |
Estimated bandwidth of the network interface if any. |
DEPENDENT | net.if.speed[«{#IFGUID}»]
Preprocessing: — JSONPATH: ⛔️ON_FAIL: — JAVASCRIPT: — DISCARD_UNCHANGED_HEARTBEAT: |
| Network interfaces | Interface {#IFNAME}({#IFALIAS}): Interface type |
The type of the network interface. |
DEPENDENT | net.if.type[«{#IFGUID}»]
Preprocessing: — JSONPATH: — DISCARD_UNCHANGED_HEARTBEAT: |
| Network interfaces | Interface {#IFNAME}({#IFALIAS}): Operational status |
The operational status of the network interface. |
DEPENDENT | net.if.status[«{#IFGUID}»]
Preprocessing: — JSONPATH: — DISCARD_UNCHANGED_HEARTBEAT: |
| Services | State of service «{#SERVICE.NAME}» ({#SERVICE.DISPLAYNAME}) |
— |
ZABBIX_ACTIVE | service.info[«{#SERVICE.NAME}»,state] |
| Status | Uptime |
The system uptime expressed in the following format:»N days, hh:mm:ss». |
ZABBIX_ACTIVE | system.uptime |
| Status | Zabbix agent ping |
The agent always returns 1 for this item. It could be used in combination with nodata() for availability check. |
ZABBIX_ACTIVE | agent.ping |
| Storage | {#DEVNAME}: Disk read rate |
Rate of read operations on the disk. |
ZABBIX_ACTIVE | perf_counter_en[«PhysicalDisk({#DEVNAME})Disk Reads/sec»,60] |
| Storage | {#DEVNAME}: Disk write rate |
Rate of write operations on the disk. |
ZABBIX_ACTIVE | perf_counter_en[«PhysicalDisk({#DEVNAME})Disk Writes/sec»,60] |
| Storage | {#DEVNAME}: Disk average queue size (avgqu-sz) |
The current average disk queue; the number of requests outstanding on the disk while the performance data is being collected. |
ZABBIX_ACTIVE | perf_counter_en[«PhysicalDisk({#DEVNAME})Current Disk Queue Length»,60] |
| Storage | {#DEVNAME}: Disk utilization by idle time |
This item is the percentage of elapsed time that the selected disk drive was busy servicing read or writes requests based on idle time. |
ZABBIX_ACTIVE | perf_counter_en[«PhysicalDisk({#DEVNAME})% Idle Time»,60]
Preprocessing: — JAVASCRIPT: |
| Storage | {#DEVNAME}: Disk read request avg waiting time |
The average time for read requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them. |
ZABBIX_ACTIVE | perf_counter_en[«PhysicalDisk({#DEVNAME})Avg. Disk sec/Read»,60] |
| Storage | {#DEVNAME}: Disk write request avg waiting time |
The average time for write requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them. |
ZABBIX_ACTIVE | perf_counter_en[«PhysicalDisk({#DEVNAME})Avg. Disk sec/Write»,60] |
| Storage | {#DEVNAME}: Average disk read queue length |
Average disk read queue, the number of requests outstanding on the disk at the time the performance data is collected. |
ZABBIX_ACTIVE | perf_counter_en[«PhysicalDisk({#DEVNAME})Avg. Disk Read Queue Length»,60] |
| Storage | {#DEVNAME}: Average disk write queue length |
Average disk write queue, the number of requests outstanding on the disk at the time the performance data is collected. |
ZABBIX_ACTIVE | perf_counter_en[«PhysicalDisk({#DEVNAME})Avg. Disk Write Queue Length»,60] |
| Zabbix raw items | Get filesystems |
The |
ZABBIX_ACTIVE | vfs.fs.get |
| Zabbix raw items | Network interfaces WMI get |
Raw data of win32_networkadapter. |
ZABBIX_ACTIVE | wmi.getall[rootcimv2,»select Name,Description,NetConnectionID,Speed,AdapterTypeId,NetConnectionStatus,GUID from win32_networkadapter where PhysicalAdapter=True and NetConnectionStatus>0″]
Preprocessing: — DISCARD_UNCHANGED_HEARTBEAT: |
| Zabbix raw items | {#FSLABEL}({#FSNAME}): Get filesystem data |
— |
DEPENDENT | vfs.fs.dependent[{#FSNAME},data]
Preprocessing: — JSONPATH: |
Triggers
| Name | Description | Expression | Severity | Dependencies and additional info |
|---|---|---|---|---|
| High CPU utilization |
The CPU utilization is too high. The system might be slow to respond. |
min(/Windows by Zabbix agent active/system.cpu.util,5m)>{$CPU.UTIL.CRIT} |
WARNING | |
| CPU interrupt time is too high |
«The CPU Interrupt Time in the last 5 minutes exceeds {$CPU.INTERRUPT.CRIT.MAX}%.» The Processor Information% Interrupt Time is the time the processor spends receiving and servicing hardware interrupts during sample intervals. This value is an indirect indicator of the activity of devices that generate interrupts, such as the system clock, the mouse, disk drivers, data communication lines, network interface cards and other peripheral devices. This is an easy way to identify a potential hardware failure. This should never be higher than 20%. |
min(/Windows by Zabbix agent active/perf_counter_en["Processor Information(_total)% Interrupt Time"],5m)>{$CPU.INTERRUPT.CRIT.MAX} |
WARNING |
Depends on: — High CPU utilization |
| CPU privileged time is too high |
The CPU privileged time in the last 5 minutes exceeds {$CPU.PRIV.CRIT.MAX}%. |
min(/Windows by Zabbix agent active/perf_counter_en["Processor Information(_total)% Privileged Time"],5m)>{$CPU.PRIV.CRIT.MAX} |
WARNING |
Depends on: — CPU interrupt time is too high — High CPU utilization |
| CPU queue length is too high |
The CPU Queue Length in the last 5 minutes exceeds {$CPU.QUEUE.CRIT.MAX}. According to actual observations, PQL should not exceed the number of cores * 2. To fine-tune the conditions, use the macro {$CPU.QUEUE.CRIT.MAX }. |
min(/Windows by Zabbix agent active/perf_counter_en["SystemProcessor Queue Length"],5m) - last(/Windows by Zabbix agent active/wmi.get[root/cimv2,"Select NumberOfLogicalProcessors from Win32_ComputerSystem"]) * 2 > {$CPU.QUEUE.CRIT.MAX} |
WARNING |
Depends on: — High CPU utilization |
| {#FSLABEL}({#FSNAME}): Disk space is critically low |
Two conditions should match: First, space utilization should be above {$VFS.FS.PUSED.MAX.CRIT:»{#FSNAME}»}. Second condition should be one of the following: — The disk free space is less than {$VFS.FS.FREE.MIN.CRIT:»{#FSNAME}»}. — The disk will be full in less than 24 hours. |
last(/Windows by Zabbix agent active/vfs.fs.dependent.size[{#FSNAME},pused])>{$VFS.FS.PUSED.MAX.CRIT:"{#FSNAME}"} and ((last(/Windows by Zabbix agent active/vfs.fs.dependent.size[{#FSNAME},total])-last(/Windows by Zabbix agent active/vfs.fs.dependent.size[{#FSNAME},used]))<{$VFS.FS.FREE.MIN.CRIT:"{#FSNAME}"} or timeleft(/Windows by Zabbix agent active/vfs.fs.dependent.size[{#FSNAME},pused],1h,100)<1d) |
AVERAGE |
Manual close: YES |
| {#FSLABEL}({#FSNAME}): Disk space is low |
Two conditions should match: First, space utilization should be above {$VFS.FS.PUSED.MAX.WARN:»{#FSNAME}»}. Second condition should be one of the following: — The disk free space is less than {$VFS.FS.FREE.MIN.WARN:»{#FSNAME}»}. — The disk will be full in less than 24 hours. |
last(/Windows by Zabbix agent active/vfs.fs.dependent.size[{#FSNAME},pused])>{$VFS.FS.PUSED.MAX.WARN:"{#FSNAME}"} and ((last(/Windows by Zabbix agent active/vfs.fs.dependent.size[{#FSNAME},total])-last(/Windows by Zabbix agent active/vfs.fs.dependent.size[{#FSNAME},used]))<{$VFS.FS.FREE.MIN.WARN:"{#FSNAME}"} or timeleft(/Windows by Zabbix agent active/vfs.fs.dependent.size[{#FSNAME},pused],1h,100)<1d) |
WARNING |
Manual close: YES Depends on: — {#FSLABEL}({#FSNAME}): Disk space is critically low |
| System time is out of sync |
The host system time is different from the Zabbix server time. |
fuzzytime(/Windows by Zabbix agent active/system.localtime,{$SYSTEM.FUZZYTIME.MAX})=0 |
WARNING |
Manual close: YES |
| System name has changed |
System name has changed. Ack to close. |
change(/Windows by Zabbix agent active/system.hostname) and length(last(/Windows by Zabbix agent active/system.hostname))>0 |
INFO |
Manual close: YES |
| Operating system description has changed |
The description of the operating system has changed. Possible reasons are that the system has been updated or replaced. Ack to close the problem manually. |
change(/Windows by Zabbix agent active/system.sw.os) and length(last(/Windows by Zabbix agent active/system.sw.os))>0 |
INFO |
Manual close: YES Depends on: — System name has changed |
| High memory utilization |
The system is running out of free memory. |
min(/Windows by Zabbix agent active/vm.memory.util,5m)>{$MEMORY.UTIL.MAX} |
AVERAGE | |
| High swap space usage |
This trigger is ignored, if there is no swap configured |
max(/Windows by Zabbix agent active/system.swap.pfree,5m)<{$SWAP.PFREE.MIN.WARN} and last(/Windows by Zabbix agent active/system.swap.size[,total])>0 |
WARNING |
Depends on: — High memory utilization |
| Number of free system page table entries is too low |
The Memory Free System Page Table Entries is less than {$MEM.PAGE_TABLE_CRIT.MIN} for 5 minutes. If the number is less than 5,000, there may well be a memory leak. |
max(/Windows by Zabbix agent active/perf_counter_en["MemoryFree System Page Table Entries"],5m)<{$MEM.PAGE_TABLE_CRIT.MIN} |
WARNING |
Depends on: — High memory utilization |
| The Memory Pages/sec is too high |
The Memory Pages/sec in the last 5 minutes exceeds {$MEM.PAGE_SEC.CRIT.MAX}. If the value is greater than 1,000, as a result of excessive paging, there may be a memory leak. |
min(/Windows by Zabbix agent active/perf_counter_en["MemoryPages/sec"],5m)>{$MEM.PAGE_SEC.CRIT.MAX} |
WARNING |
Depends on: — High memory utilization |
| Zabbix agent: active checks are not available |
Active checks are considered unavailable. Agent is not sending heartbeat for prolonged time. |
min(/Windows by Zabbix agent active/zabbix[host,active_agent,available],{$AGENT.TIMEOUT})=2 |
HIGH | |
| Interface {#IFNAME}({#IFALIAS}): High bandwidth usage |
The network interface utilization is close to its estimated maximum bandwidth. |
(avg(/Windows by Zabbix agent active/net.if.in["{#IFGUID}"],15m)>({$IF.UTIL.MAX:"{#IFNAME}"}/100)*last(/Windows by Zabbix agent active/net.if.speed["{#IFGUID}"]) or avg(/Windows by Zabbix agent active/net.if.out["{#IFGUID}"],15m)>({$IF.UTIL.MAX:"{#IFNAME}"}/100)*last(/Windows by Zabbix agent active/net.if.speed["{#IFGUID}"])) and last(/Windows by Zabbix agent active/net.if.speed["{#IFGUID}"])>0
Recovery expression:
|
WARNING |
Manual close: YES Depends on: — Interface {#IFNAME}({#IFALIAS}): Link down |
| Interface {#IFNAME}({#IFALIAS}): High error rate |
Recovers when below 80% of {$IF.ERRORS.WARN:»{#IFNAME}»} threshold |
min(/Windows by Zabbix agent active/net.if.in["{#IFGUID}",errors],5m)>{$IF.ERRORS.WARN:"{#IFNAME}"} or min(/Windows by Zabbix agent active/net.if.out["{#IFGUID}",errors],5m)>{$IF.ERRORS.WARN:"{#IFNAME}"}
Recovery expression:
|
WARNING |
Manual close: YES Depends on: — Interface {#IFNAME}({#IFALIAS}): Link down |
| Interface {#IFNAME}({#IFALIAS}): Ethernet has changed to lower speed than it was before |
This Ethernet connection has transitioned down from its known maximum speed. This might be a sign of autonegotiation issues. Ack to close. |
change(/Windows by Zabbix agent active/net.if.speed["{#IFGUID}"])<0 and last(/Windows by Zabbix agent active/net.if.speed["{#IFGUID}"])>0 and last(/Windows by Zabbix agent active/net.if.status["{#IFGUID}"])=2 |
INFO |
Manual close: YES Depends on: — Interface {#IFNAME}({#IFALIAS}): Link down |
| Interface {#IFNAME}({#IFALIAS}): Link down |
This trigger expression works as follows: 1. Can be triggered if operations status is down. 2. {$IFCONTROL:»{#IFNAME}»}=1 — user can redefine Context macro to value — 0. That marks this interface as not important. No new trigger will be fired if this interface is down. 3. {TEMPLATE_NAME:METRIC.diff()}=1) — trigger fires only if operational status is different from Connected(2). WARNING: if closed manually — won’t fire again on next poll, because of .diff. |
{$IFCONTROL:"{#IFNAME}"}=1 and last(/Windows by Zabbix agent active/net.if.status["{#IFGUID}"])<>2 and (last(/Windows by Zabbix agent active/net.if.status["{#IFGUID}"],#1)<>last(/Windows by Zabbix agent active/net.if.status["{#IFGUID}"],#2))
Recovery expression:
|
AVERAGE |
Manual close: YES |
| «{#SERVICE.NAME}» ({#SERVICE.DISPLAYNAME}) is not running |
The service has a state other than «Running» for the last three times. |
min(/Windows by Zabbix agent active/service.info["{#SERVICE.NAME}",state],#3)<>0 |
AVERAGE | |
| Host has been restarted |
The device uptime is less than 10 minutes. |
last(/Windows by Zabbix agent active/system.uptime)<10m |
WARNING |
Manual close: YES |
| Zabbix agent is not available |
For active agents, nodata() with agent.ping is used with {$AGENT.NODATA_TIMEOUT} as time threshold. |
nodata(/Windows by Zabbix agent active/agent.ping,{$AGENT.NODATA_TIMEOUT})=1 |
AVERAGE |
Manual close: YES |
| {#DEVNAME}: Disk is overloaded |
The disk appears to be under heavy load |
min(/Windows by Zabbix agent active/perf_counter_en["PhysicalDisk({#DEVNAME})% Idle Time",60],15m)>{$VFS.DEV.UTIL.MAX.WARN} |
WARNING |
Manual close: YES Depends on: — {#DEVNAME}: Disk read request responses are too high — {#DEVNAME}: Disk write request responses are too high |
| {#DEVNAME}: Disk read request responses are too high |
This trigger might indicate disk {#DEVNAME} saturation. |
min(/Windows by Zabbix agent active/perf_counter_en["PhysicalDisk({#DEVNAME})Avg. Disk sec/Read",60],15m) > {$VFS.DEV.READ.AWAIT.WARN:"{#DEVNAME}"} |
WARNING |
Manual close: YES |
| {#DEVNAME}: Disk write request responses are too high |
This trigger might indicate disk {#DEVNAME} saturation. |
min(/Windows by Zabbix agent active/perf_counter_en["PhysicalDisk({#DEVNAME})Avg. Disk sec/Write",60],15m) > {$VFS.DEV.WRITE.AWAIT.WARN:"{#DEVNAME}"} |
WARNING |
Manual close: YES |
Feedback
Please report any issues with the template at https://support.zabbix.com.
You can also provide feedback, discuss the template, or ask for help at ZABBIX forums.
I’m trying to monitor CPU utilization of windows 7 32bit PC (C2D E8400) using zabbix.
I tried both «perf_counter[Processor Information(_Total)% Processor Time]» and «system.cpu.util[,system,avg5]». After some time status of these items reverted itself to «Unsupported».
Is this problem on agent side, or at server? How to fix it? Ideally I want to see percentages load per each core.
UPD: topic and description updated.
UPD2: these counters work, but their value are float, and not decimal as I thought.
asked Jan 5, 2011 at 15:04
![]()
1
CPU load (what you have) is not the same as CPU utilization (what you’re trying to get). Load is a measurement of the average number of processes waiting on the processor(s), whilst utilization is the amount of time the processor was doing work during a given time snapshot. You probably want to look at the counter:
perf_counter[Processor(_Total)% Processor Time]
It’s been a while since I’ve used zabbix, so syntax might have changed.
answered Jan 5, 2011 at 17:03
![]()
Jon AnglissJon Angliss
1,79210 silver badges8 bronze badges
4
I just added the items and triggers for:
system.cpu.util[,,avg1]
system.cpu.util[,,avg5]
system.cpu.util[,,avg15]
It is working in Zabbix Agent 2.0.4 and Windows 2008. Because have differences between CPU Load and CPU Utilization.
![]()
Daniel t.
9,1411 gold badge32 silver badges36 bronze badges
answered Feb 28, 2013 at 18:38
![]()
Содержание
- Русские Блоги
- Zabbix CPU load、CPU utlization、CPU jumps
- Во-первых, загрузка ЦП
- Два, загрузка процессора
- Мониторинг использования CPU в Zabbix
- Мониторим ядра CPU в Zabbix и создаем произвольные счетчики в Low-level discovery
- Documentation
- Sidebar
- Table of Contents
- Windows Zabbix agent
- Overview
- Shared items
- Windows-specific items
- Monitoring Windows services
- Discovery of Windows services
Русские Блоги
Zabbix CPU load、CPU utlization、CPU jumps
Во-первых, загрузка ЦП

Используйте Zabbix, чтобы проверить загрузку ЦП, будут следующие значения:
- Время простоя ЦП: отношение времени простоя ЦП [для краткости id]
- Пользовательское время ЦП: время ЦП, используемое в пользовательском режиме [именуемое нами]
- Системное время ЦП: соотношение времени ЦП, используемое в системном режиме [сокращенно sy]
- CPU iowait time: CPU ожидает времени завершения записи на диск [wa]
- Хорошее время ЦП: соотношение времени ЦП в пользовательском режиме, используемое в качестве хорошо взвешенного распределения процесса [обозначается как ni]
- Время прерывания ЦП: время использования аппаратного прерывания [привет]
- CPU softirq time: время использования жесткого прерывания [si]
- Время кражи ЦП: время кражи виртуальной машины [именуемое st]
Фактически, эти данные получаются с помощью команды top в системе Linux: 
Два, загрузка процессора

Загрузка процессора обеспечивает 1 минуту, 5 минут и 15 минут одноядерной загрузки процессора.
Мы обнаружим, что данные, предоставляемые Zabbix, сильно отличаются от данных средней нагрузки, выводимых командой top, потому что top подсчитывает общее количество ядер.
Кроме того, Zabbix настроен с двумя триггерами
Источник
Мониторинг использования CPU в Zabbix
Приведу пример мониторинга использования каждого ядра процессора используя Zabbix.
Допустим на высоконагруженном NAT сервере основная нагрузка от softirq, присутствует один процессор с 8 ядрами, а также на сервере установлен Zabbix агент.
И чтобы увидеть равномерно ли распределены прерывания сетевого адаптера по ядрам процессора, создадим элементы данных на Zabbix сервере, в которых укажем:
Тип: Zabbix агент
Тип информации: Числовой (с плавающей точкой)
Единица измерения: %
А также ключ:
Где 0 — номер процессора, softirq — тип нагрузки, avg5 — средняя нагрузка за 5 минут. Аналогично создадим элементы данных для других ядер процессора с ключами, а также добавим их на один график:
Вместо softirq можно указать idle, nice, user (по умолчанию для Linux), system (по умолчанию для Windows), iowait, interrupt, softirq, steal, guest, guest_nice.
А вместо avg5 можно указать: avg1 (среднее за одну минуту, по умолчанию) или avg15 (среднее за 15 минут).

Чтобы не указывать ядра процессоров вручную, можно создать правило обнаружения:
И указать в нем элемент данных, например:
Также можно создать триггер, чтобы узнать когда значение будет больше 90:
Ниже приведу примеры элементов данных, которые отображают различную информацию о CPU, кстати эти элементы данных по умолчанию присутствуют в шаблоне «Template OS Linux».
Источник
Мониторим ядра CPU в Zabbix и создаем произвольные счетчики в Low-level discovery
Не так давно тут проходила статья про LLD. Мне она показалась скучной т.к. описывает примерно то же, что есть и в документации. Я решил пойти дальше и с помощью LLD мониторить те параметры, которые раньше нельзя было мониторить автоматически, либо это было достаточно сложно. Разберем работу LLD на примере логических процессоров в Windows: 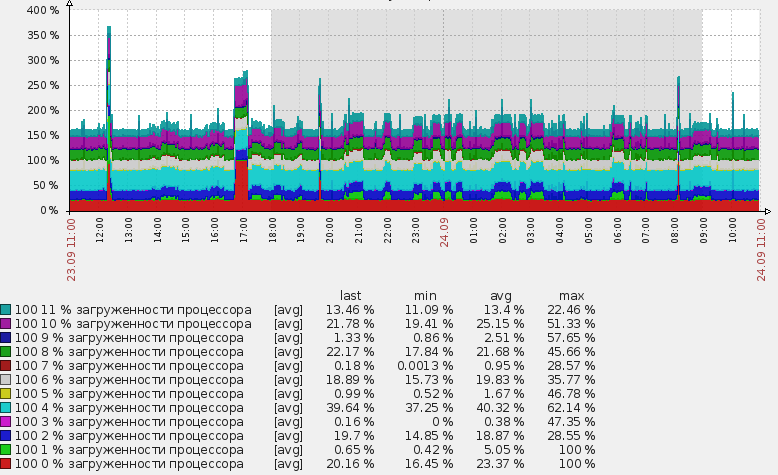
Изначально интересовал расширенный монтиринг помимо ядрер CPU и нагрузка на физические диски. До того как обнаружение было введено, эти задачи частично решались ручным добавлением. Я добавлял условные диски в файл конфигурации zabbix_agent и вообще по-разному извращался. В результате это было очень неудобно, добавлялось много неприятной ручной работы и вообще неправильно в общем как-то было 🙂
В итоге получается схема, которая автоматически определяет ядра в системе, а также физические диски, установленные в системе и добавляет необходимые элементы сбора данных. Для того, чтобы узнать как это реализовать у себя, добро пожаловать под кат. Я попытаюсь более-менее подробно расписать работу на примере CPU и то как сделать тоже самое, но для физических дисков.
Тип отправляемых данных
Для начала стоит отослать к документации, где расписывается что такое LLD и с чем его едят. Помимо стандартных шаблонов нас будет интересовать 4-ый раздел с описание JSON формата обнаружения. То есть мы будем создавать свой собственный метод обнаружения. По сути все сводится к вызову скрипта, который формирует в нужном формате нужные данные.
Создаем скрипт.
Для скрипта я выбрал powershell. Его я знаю немного лучше других скриптовых языков, да и учитывая, что все будет крутиться во круг WMI, сделать его можно было бы и на VBS.
Итак, скрипт.
Задача скрипта состоит в том, чтобы определить число логических процессоров с помощью WMI и вывести в консоль эти данные в формате JSON. Передавать мы будем переменную с именем , а также ее значения. Формат вывода будет примерно таким, в зависимости от количества логических процессоров:
Скрипт формирования данных
Сам скрипт выглядит так:
Сейчас мы получаем, что при запуске скрипта он узнает сколько ядер и формирует пакет для отправки.
Что же мы делаем дальше? Нужно создать Discovery rule.
Добавялем низкоуровневое обнаружение в настройках zabbix сервера
Для этого заходим в нужный шаблон, который добавлен к интересующим нас хостам, в раздел Discovery и нажимаем кнопку Create discovery rule. 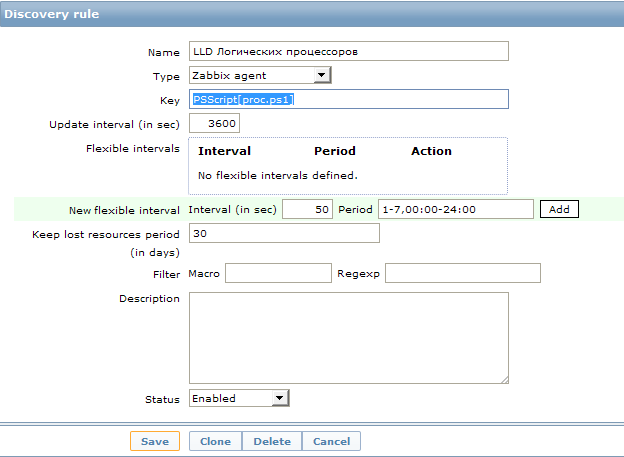
Тут мы видим непонятное значение поля key: PSScript[proc.ps1]. Это UserParameter. Этот пункт создан для удобства, теперь в каждом новом объекте мы можем просто вписывать параметр в виде имени PS скрипта и он будет искать его в заранее оговоренном месте. Сам параметр прописывается в файле конфигурации клиента (обычно называется zabbix_agentd.conf) и выглядит так:
Мы создали новое правило обнаружения с пользовательским сбором данных. Запрос на изменение информации задан как 1 час. Пожалуй, для таких статических данных, как количество процессоров, это слишком часто :), но каждый волен поставить свое значение. Для первоначального сбора данных и отладки лучше это значение уменьшить до совсем небольших значений, чтобы не ждать часами выполнение скрипта.
Настройка прототипов данных
Хорошо. Данные о количестве процессоров мы начали собирать. Но в результате нам нужны не эти данные, а новый item в мониторинге. Именно item может собирать данные, а не наш скрипт, наш скрипт служит только для обнаружения самих элементов для сбора данных.
А для того что бы создать новый элемент сбора данных, полученный на основании LLD, в том же разделе Discovery мы создаем новый прототип. Для этого заходим в item prototypes и нажимаем create item prototype. Я создал вот такой элемент сбора: 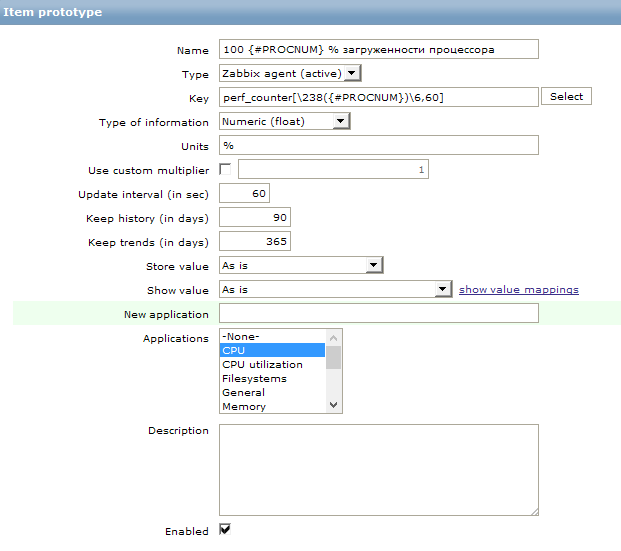
Для сбора данных используется стандартный счетчик производительности. В zabbix для сбора этих данных есть ключ perf_counter. Вместо номера логического ядра мы вставляем полученное значение в виде переменной из раздела Discovery.
Теперь все готово. Или почти все…
С этого момента, когда скрипт discovery обнаружит логические процессоры, для этого хоста будут созданы элементы сбора данных созданных точно для этого количества процессоров.
И теперь если мы зайдем в items для хоста, низкоуровневое обнаружение для которого уже отработало, то мы увидим, что появились новые элементы: 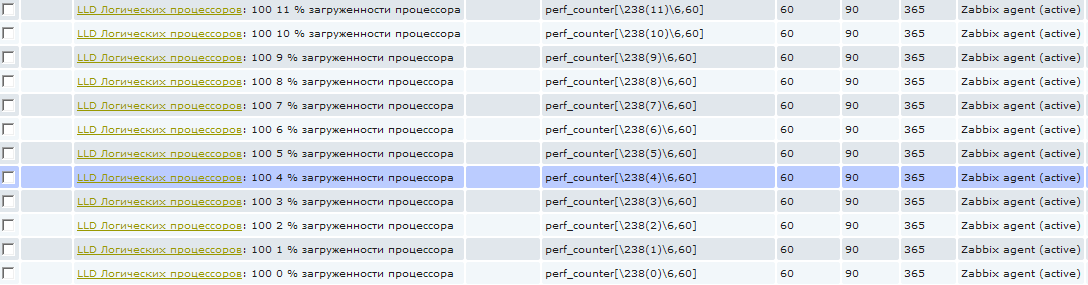
Эти элементы нельзя удалить стандартным способом, т.к. они созданы автоматически, они выделены особенным префиксом с названием правила низкоуровневого обнаружения. На скриншоте кажется, что написана какая-то фигня в имени :), на самом деле все просто, я использую трехзначный код в каждом имени для сортировки. То есть 100 это только лишь сортировочный номер. Следующая цифра от 0 до 11 это номер логического процессора. А дальше уже «% загруженности процессора». А то сначала может показаться, что это 0% загруженности процессора и я пытаюсь это значение собрать 🙂
Единственный недостаток всего этого метода в том, что график, такой как в заголовке этого поста, нельзя создать с помощью механизма низкоуровневого обнаружения. То есть мы можем, конечно, создать не только item, но и graph объект для каждого логического процессора, но создать один суммарный график автоматически со всеми обнаруженными логическими процессорами не получится. По крайней мере я не видел как это можно было бы сделать, на форуме zabbix мне также не смогли подсказать. Это, конечно, не особенно серьезный недостаток, но если у вас 200 хостов, это может стать проблемой :). Ведь график для каждого хоста нужно будет создавать вручную.
Мониторим производительность каждого физического диска в системе
В вышеприведённом способе лучше разобраться и тогда это открывает достаточно широкие возможности для мониторинга объектов в системе, количество которых либо отличается от хоста к хосту либо их количество во все изменяется во время работы.
Например, часто случается, что нужно определить, не происходил ли недостаток в ресурсах физического диска, установленного в сервере. Чаще всего эти данные сложно уловить в реалтайме и хочется иметь их собранными постфактум. Для этого я ввел аналогичное обнаружение и для физических дисков для сбора обширной статистики по ним. И, в отличии от процессоров, элементов сбора данных я создал их с избытком. 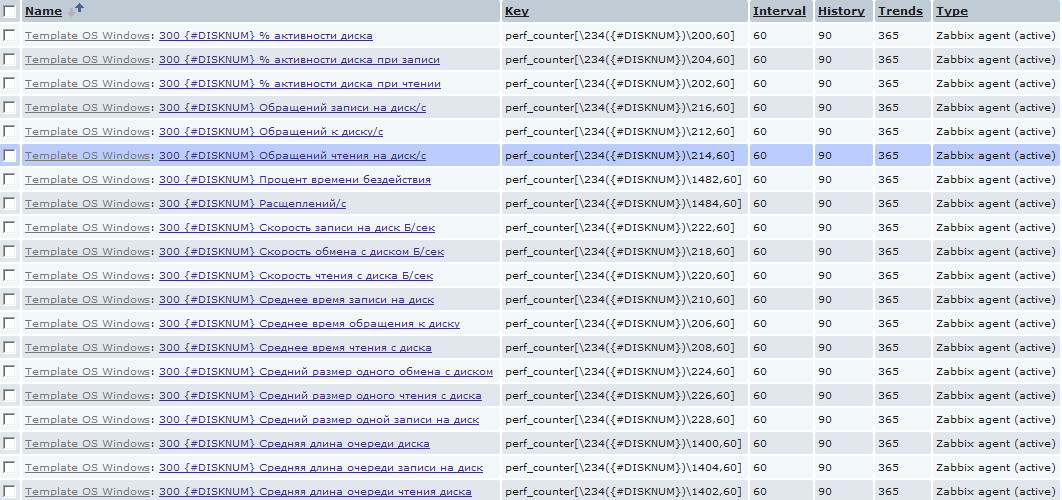
Тут, конечно, надо быть внимательным и если mysql у вас стоит на каком-нибудь стареньком забитом компе, то подобное количество достаточно быстро унесет вашу базу данных в небеса. Т.к. в приведенном примере для каждого хоста создается для каждого физического диска 20 новых элементов, которые будут создавать одного новое значение в минуту. В масштабе пары десятков серверов с кучами разных дисков это выливается в более-менее весомое количество данных. Но тут каждый волен выбирать свой путь самурая 🙂
Скрипт для LLD физических дисков выглядит так:
Добавляем новое правило обнаружения по аналогии с CPU. Точно также мы создаем нужные элементы в discovery.
Вообще, конечно, этот механизм дает довольно большие возможности по определению различных элементов для мониторинга. Таким же способом можно, например, добавить мониторинг сетевых интерфейсов, процессов в системе, служб и любых других элементов, имя которых и количество заранее неизвестно.
Надеюсь эта статья кому-нибудь поможет разобраться с LLD. С удовольствием отвечу на возникшие вопросы.
Источник
Documentation
Table of Contents
Windows Zabbix agent
Overview
The Windows Zabbix agent items are presented in two lists:
- Shared items — the item keys that are shared with the UNIX Zabbix agent
- Windows-specific items — the item keys that are supported only on Windows:
- eventlog[]
- net.if.list
- perf_counter[]
- perf_counter_en[]
- perf_instance.discovery[]
- proc_info[]
- registry.data[]
- registry.get[]
- service.discovery
- service.info[]
- services
- vm.vmemory.size[]
- wmi.get[]
- wmi.getall[]
Windows-specific items sometimes are an approximate counterpart of a similar agent item, for example proc_info , supported on Windows, roughly corresponds to the proc.mem item, not supported on Windows.
Note that all item keys supported by Zabbix agent on Windows are also supported by the new generation Zabbix agent 2. See the additional item keys that you can use with the agent 2 only.
Shared items
The table below lists Zabbix agent items that are supported on Windows and are shared with the UNIX Zabbix agent:
- The item key is a link to full details in the UNIX Zabbix agent item group
- The item key signature includes only those parameters that are supported on Windows
- Windows-relevant item comments are included
| Item key | Comments |
|---|---|
| agent.hostmetadata | |
| agent.hostname | |
| agent.ping | |
| agent.variant | |
| agent.version | |
| log[file, , , , , , , ] | This item is not supported for Windows Event Log. The persistent_dir parameter is not supported on Windows. |
| log.count[file, , , , , , ] | This item is not supported for Windows Event Log. The persistent_dir parameter is not supported on Windows. |
| logrt[file_regexp, , , , , , , ] | This item is not supported for Windows Event Log. The persistent_dir parameter is not supported on Windows. |
| logrt.count[file_regexp, , , , , , ] | This item is not supported for Windows Event Log. The persistent_dir parameter is not supported on Windows. |
| modbus.get[endpoint, , ,, , , , ] | |
| net.dns[ ,name, , , , |
] The ip , timeout and count parameters are ignored on Windows. net.dns.record[ ,name, , , ,
] The ip , timeout and count parameters are ignored on Windows. net.if.discovery Some Windows versions (for example, Server 2008) might require the latest updates installed to support non-ASCII characters in interface names. net.if.in[if, ] On Windows, the item gets values from 64-bit counters if available. 64-bit interface statistic counters were introduced in Windows Vista and Windows Server 2008. If 64-bit counters are not available, the agent uses 32-bit counters.
Multi-byte interface names on Windows are supported.
You may obtain network interface descriptions on Windows with net.if.discovery or net.if.list items. net.if.out[if, ] On Windows, the item gets values from 64-bit counters if available. 64-bit interface statistic counters were introduced in Windows Vista and Windows Server 2008. If 64-bit counters are not available, the agent uses 32-bit counters.
Multi-byte interface names on Windows are supported.
You may obtain network interface descriptions on Windows with net.if.discovery or net.if.list items. net.if.total[if, ] On Windows, the item gets values from 64-bit counters if available. 64-bit interface statistic counters were introduced in Windows Vista and Windows Server 2008. If 64-bit counters are not available, the agent uses 32-bit counters.
You may obtain network interface descriptions on Windows with net.if.discovery or net.if.list items. net.tcp.listen[port] net.tcp.port[ ,port] net.tcp.service[service, ,
] Checking of LDAP and HTTPS on Windows is only supported by Zabbix agent 2. net.tcp.service.perf[service, ,
] Checking of LDAP and HTTPS on Windows is only supported by Zabbix agent 2. * net.tcp.socket.count[ , , , , ] *This item is supported on Linux by Zabbix agent, but on Windows it is supported only by Zabbix agent 2 on 64-bit Windows. net.udp.service[service, ,
] * net.udp.socket.count[ , , , , ] *This item is supported on Linux by Zabbix agent, but on Windows it is supported only by Zabbix agent 2 on 64-bit Windows. proc.num[ , ] On Windows, only the name and user parameters are supported. system.cpu.discovery system.cpu.load[ , ] system.cpu.num[ ] system.cpu.util[ , , ] The value is acquired using the Processor Time performance counter. Note that since Windows 8 its Task Manager shows CPU utilization based on the Processor Utility performance counter, while in previous versions it was the Processor Time counter.
system is the only type parameter supported on Windows. system.hostname[ , ] The value is acquired by either GetComputerName() (for netbios) or gethostname() (for host) functions on Windows.
Examples of returned values:
=> system.hostname в†’ WIN-SERV2008-I6
=> system.hostname[host] в†’ Win-Serv2008-I6LonG
=> system.hostname[host,lower] в†’ win-serv2008-i6long
See also a more detailed description. system.localtime[ ] system.run[command, ] system.sw.arch system.swap.size[ , ] The pused type parameter is supported on Linux by Zabbix agent, but on Windows it is supported only by Zabbix agent 2.
Note that this key might report incorrect swap space size/percentage on virtualized (VMware ESXi, VirtualBox) Windows platforms. In this case you may use the perf_counter[700(_Total)702] key to obtain correct swap space percentage. system.uname Example of returned value:
Windows ZABBIX-WIN 6.0.6001 MicrosoftВ® Windows ServerВ® 2008 Standard Service Pack 1 x86
On Windows the value for this item is obtained from Win32_OperatingSystem and Win32_Processor WMI classes. The OS name (including edition) might be translated to the user’s display language. On some versions of Windows it contains trademark symbols and extra spaces. system.uptime vfs.dir.count[dir, , , , , , , , , , ] On Windows, directory symlinks are skipped and hard links are counted only once.
1AppDataLocalTemp»] — monitors the number of files in temporary directory vfs.dir.get[dir, , , , , , , , , , ] On Windows, directory symlinks are skipped and hard links are counted only once.
1AppDataLocalTemp»] — retrieves the file list in temporary directory vfs.dir.size[dir, , , , , ] On Windows any symlink is skipped and hard links are taken into account only once. vfs.file.cksum[file, ] vfs.file.contents[file, ] vfs.file.exists[file, , ] On Windows the double quotes have to be backslash ‘’ escaped and the whole item key enclosed in double quotes when using the command line utility for calling zabbix_get.exe or agent2.
Note that the item may turn unsupported on Windows if a directory is searched within a non-existing directory, e.g. vfs.file.exists[C:nodir,dir] (where ‘no’ does not exist). vfs.file.get[file] Supported file types on Windows: regular file, directory, symbolic link vfs.file.md5sum[file] vfs.file.owner[file, , ] vfs.file.regexp[,regexp, , , , ] vfs.file.regmatch[file,regexp, , , ] vfs.file.size[file, ] vfs.file.time[file, ] On Windows XP vfs.file.time[file,change] may be equal to vfs.file.time[file,access]. vfs.fs.discovery The <#FSLABEL>macro is supported on Windows since Zabbix 6.0. vfs.fs.get The <#FSLABEL>macro is supported on Windows since Zabbix 6.0. vfs.fs.size[fs, ] vm.memory.size[ ] web.page.get[host,
Windows-specific items
The table provides details on the item keys that are supported only by the Windows Zabbix agent.
| Item key | |||
|---|---|---|---|
| Description | Return value | Parameters | Comments |
| eventlog[name, , , , , , ] | |||
| Event log monitoring. | Log | name — name of event log regexp — regular expression describing the required pattern severity — regular expression describing severity (case-insensitive) This parameter accepts the following values: «Information», «Warning», «Error», «Critical», «Verbose» (since Zabbix 2.2.0 running on Windows Vista or newer) source — regular expression describing source identifier (case-insensitive; regular expression is supported since Zabbix 2.2.0) eventid — regular expression describing the event identifier(s) maxlines — maximum number of new lines per second the agent will send to Zabbix server or proxy. This parameter overrides the value of ‘MaxLinesPerSecond’ in zabbix_agentd.win.conf mode — possible values: all (default), skip — skip processing of older data (affects only newly created items). |
The item must be configured as an active check. |
Examples:
=> eventlog[Application]
=> eventlog[Security,,»Failure Audit»,,^(529|680)$]
=> eventlog[System,,»Warning|Error»]
=> eventlog[System. ^1$]
=> eventlog[System. @TWOSHORT] — here a custom regular expression named TWOSHORT is referenced (defined as a Result is TRUE type, the expression itself being ^1$|^70$ ).
Note that the agent is unable to send in events from the «Forwarded events» log.
The mode parameter is supported since Zabbix 2.0.0.
«Windows Eventing 6.0» is supported since Zabbix 2.2.0.
Note that selecting a non-Log type of information for this item will lead to the loss of local timestamp, as well as log severity and source information.
See also additional information on log monitoring. net.if.list Network interface list (includes interface type, status, IPv4 address, description). Text Supported since Zabbix agent version 1.8.1. Multi-byte interface names supported since Zabbix agent version 1.8.6. Disabled interfaces are not listed.
Note that enabling/disabling some components may change their ordering in the Windows interface name.
Some Windows versions (for example, Server 2008) might require the latest updates installed to support non-ASCII characters in interface names. perf_counter[counter, ] Value of any Windows performance counter. Integer, float, string or text (depending on the request) counter — path to the counter
interval — last N seconds for storing the average value.
The interval must be between 1 and 900 seconds (included) and the default value is 1. Performance Monitor can be used to obtain list of available counters. Until version 1.6 this parameter will return correct value only for counters that require just one sample (like SystemThreads). It will not work as expected for counters that require more than one sample — like CPU utilization. Since 1.6, interval is used, so the check returns an average value for last «interval» seconds every time.
See also: Windows performance counters. perf_counter_en[counter, ] Value of any Windows performance counter in English. Integer, float, string or text (depending on the request) counter — path to the counter in English
interval — last N seconds for storing the average value.
The interval must be between 1 and 900 seconds (included) and the default value is 1. This item is only supported on Windows Server 2008/Vista and above.
You can find the list of English strings by viewing the following registry key: HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindows NTCurrentVersionPerflib09 .
Supported since Zabbix agent versions 4.0.13 and 4.2.7. perf_instance.discovery[object] List of object instances of Windows performance counters. Used for low-level discovery. JSON object object — object name (localized) Supported since Zabbix agent version 5.0.1. perf_instance_en.discovery[object] List of object instances of Windows performance counters, discovered using object names in English. Used for low-level discovery. JSON object object — object name (in English) Supported since Zabbix agent version 5.0.1. proc_info[process,, ] Various information about specific process(es). Float process — process name
attribute — requested process attribute
type — representation type (meaningful when more than one process with the same name exists) The following attributes are supported:
vmsize (default) — size of process virtual memory in Kbytes
wkset — size of process working set (amount of physical memory used by process) in Kbytes
pf — number of page faults
ktime — process kernel time in milliseconds
utime — process user time in milliseconds
io_read_b — number of bytes read by process during I/O operations
io_read_op — number of read operation performed by process
io_write_b — number of bytes written by process during I/O operations
io_write_op — number of write operation performed by process
io_other_b — number of bytes transferred by process during operations other than read and write operations
io_other_op — number of I/O operations performed by process, other than read and write operations
gdiobj — number of GDI objects used by process
userobj — number of USER objects used by process
Valid types are:
avg (default) — average value for all processes named
min — minimum value among all processes named
max — maximum value among all processes named
sum — sum of values for all processes named
Examples:
=> proc_info[iexplore.exe,wkset,sum] — to get the amount of physical memory taken by all Internet Explorer processes
=> proc_info[iexplore.exe,pf,avg] — to get the average number of page faults for Internet Explorer processes
Note that on a 64-bit system, a 64-bit Zabbix agent is required for this item to work correctly.
Note: io_*, gdiobj and userobj attributes are available only on Windows 2000 and later versions of Windows, not on Windows NT 4.0. registry.data[key, ] Return data for the specified value name in the Windows Registry key. Integer, string or text (depending on the value type) key — registry key including the root key; root abbreviations (e.g. HKLM) are allowed
value name — registry value name in the key (empty string «» by default). The default value is returned if the value name is not supplied. Supported root abbreviations:
HKCR — HKEY_CLASSES_ROOT
HKCC — HKEY_CURRENT_CONFIG
HKCU — HKEY_CURRENT_USER
HKCULS — HKEY_CURRENT_USER_LOCAL_SETTINGS
HKLM — HKEY_LOCAL_MACHINE
HKPD — HKEY_PERFORMANCE_DATA
HKPN — HKEY_PERFORMANCE_NLSTEXT
HKPT — HKEY_PERFORMANCE_TEXT
HKU — HKEY_USERS
Keys with spaces must be double-quoted.
Examples:
=> registry.data[«HKEY_LOCAL_MACHINEError Reporting»] — return the data of the default value of this key
=> registry.data[«HKLMError Reporting»,»EnableZip»] — return the data of the value named «Enable Zip» in this key
This key is supported since Zabbix 6.2.0. registry.get[key, , ] List of Windows Registry values or keys located at given key. JSON key — registry key including the root key; root abbreviations (e.g. HKLM) are allowed (see comments for registry.data[] to see full list of abbreviations)
mode — possible values:
values (default), keys
name regexp — only discover values with names that match the regexp (default — discover all values). Allowed only with values as mode . Keys with spaces must be double-quoted.
Examples:
=> registry.get[HKLM,values,»^DisplayName|DisplayVersion$»] — return the data of the values named «DisplayName» or «DisplayValue» in this key. The JSON will include details of the key, last subkey, value name, value type and value data.
=> registry.get[HKLM,values] — return the data of the all values in this key. The JSON will include details of the key, last subkey, value name, value type and value data.
=> registry.get[HKLM,keys] — return all subkeys of this key. The JSON will include details of the key and last subkey.
This key is supported since Zabbix 6.2.0. service.discovery List of Windows services. Used for low-level discovery. JSON object Supported since Zabbix agent version 3.0. service.info[service,
] Information about a service. Integer — with param as state, startup
String — with param as displayname, path, user
Text — with param as description
Specifically for state:
0 — running,
1 — paused,
2 — start pending,
3 — pause pending,
4 — continue pending,
5 — stop pending,
6 — stopped,
7 — unknown,
255 — no such service
Specifically for startup:
0 — automatic,
1 — automatic delayed,
2 — manual,
3 — disabled,
4 — unknown,
5 — automatic trigger start,
6 — automatic delayed trigger start,
7 — manual trigger start service — a real service name or its display name as seen in MMC Services snap-in
param — state (default), displayname, path, user, startup or description Examples:
=> service.info[SNMPTRAP] — state of the SNMPTRAP service
=> service.info[SNMP Trap] — state of the same service, but with display name specified
=> service.info[EventLog,startup] — startup type of the EventLog service
Items service.info[service,state] and service.info[service] will return the same information.
Note that only with param as state this item returns a value for non-existing services (255).
This item is supported since Zabbix 3.0.0. It should be used instead of the deprecated service_state[service] item. services[ , , ] Listing of services. 0 — if empty
Text — list of services separated by a newline type — all (default), automatic, manual or disabled
state — all (default), stopped, started, start_pending, stop_pending, running, continue_pending, pause_pending or paused
exclude — services to exclude from the result. Excluded services should be listed in double quotes, separated by comma, without spaces. Examples:
=> services[,started] — list of started services
=> services[automatic, stopped] — list of stopped services, that should be run
=> services[automatic, stopped, «service1,service2,service3»] — list of stopped services, that should be run, excluding services with names service1, service2 and service3
The exclude parameter is supported since Zabbix 1.8.1. vm.vmemory.size[ ] Virtual memory size in bytes or in percentage from total. Integer — for bytes
Float — for percentage type — possible values:
available (available virtual memory), pavailable (available virtual memory, in percent), pused (used virtual memory, in percent), total (total virtual memory, default), used (used virtual memory) Example:
=> vm.vmemory.size[pavailable] в†’ available virtual memory, in percentage
Monitoring of virtual memory statistics is based on:
* Total virtual memory on Windows (total physical + page file size);
* The maximum amount of memory Zabbix agent can commit;
* The current committed memory limit for the system or Zabbix agent, whichever is smaller.
This key is supported since Zabbix 3.0.7 and 3.2.3. wmi.get[ , ] Execute WMI query and return the first selected object. Integer, float, string or text (depending on the request) namespace — WMI namespace
query — WMI query returning a single object WMI queries are performed with WQL.
Example:
=> wmi.get[rootcimv2,select status from Win32_DiskDrive where Name like ‘%PHYSICALDRIVE0%’] — returns the status of the first physical disk
This key is supported since Zabbix 2.2.0. wmi.getall[ , ] Execute WMI query and return the whole response.
Can be used for low-level discovery. JSON object namespace — WMI namespace
query — WMI query WMI queries are performed with WQL.
Example:
=> wmi.getall[rootcimv2,select * from Win32_DiskDrive where Name like ‘%PHYSICALDRIVE%’] — returns status information of physical disks
JSONPath preprocessing can be used to point to more specific values in the returned JSON.
This key is supported since Zabbix 4.4.0.
Monitoring Windows services
This tutorial provides step-by-step instructions for setting up the monitoring of Windows services. It is assumed that Zabbix server and agent are configured and operational.
Step 1
Get the service name.
You can get that name by going to MMC Services snap-in and bringing up the properties of the service. In the General tab you should see a field called ‘Service name’. The value that follows is the name you will use when setting up an item for monitoring.
For example, if you wanted to monitor the «workstation» service then your service might be: lanmanworkstation.
Step 2
Configure an item for monitoring the service.
The item service.info[service,
] retrieves the information about a particular service. Depending on the information you need, specify the param option which accepts the following values: displayname, state, path, user, startup or description. The default value is state if param is not specified (service.info[service]).
The type of return value depends on chosen param: integer for state and startup; character string for displayname, path and user; text for description.
- Key: service.info[lanmanworkstation]
- Type of information: Numeric (unsigned)
- Show value: select the Windows service state value mapping
Two value maps are available Windows service state and Windows service startup type to map a numerical value to a text representation in the Frontend.
Discovery of Windows services
Low-level discovery provides a way to automatically create items, triggers, and graphs for different entities on a computer. Zabbix can automatically start monitoring Windows services on your machine, without the need to know the exact name of a service or create items for each service manually. A filter can be used to generate real items, triggers, and graphs only for services of interest.
Источник
Не так давно тут проходила статья про LLD. Мне она показалась скучной т.к. описывает примерно то же, что есть и в документации. Я решил пойти дальше и с помощью LLD мониторить те параметры, которые раньше нельзя было мониторить автоматически, либо это было достаточно сложно. Разберем работу LLD на примере логических процессоров в Windows:
Изначально интересовал расширенный монтиринг помимо ядрер CPU и нагрузка на физические диски. До того как обнаружение было введено, эти задачи частично решались ручным добавлением. Я добавлял условные диски в файл конфигурации zabbix_agent и вообще по-разному извращался. В результате это было очень неудобно, добавлялось много неприятной ручной работы и вообще неправильно в общем как-то было 
В итоге получается схема, которая автоматически определяет ядра в системе, а также физические диски, установленные в системе и добавляет необходимые элементы сбора данных. Для того, чтобы узнать как это реализовать у себя, добро пожаловать под кат. Я попытаюсь более-менее подробно расписать работу на примере CPU и то как сделать тоже самое, но для физических дисков.
Тип отправляемых данных
Для начала стоит отослать к документации, где расписывается что такое LLD и с чем его едят. Помимо стандартных шаблонов нас будет интересовать 4-ый раздел с описание JSON формата обнаружения. То есть мы будем создавать свой собственный метод обнаружения. По сути все сводится к вызову скрипта, который формирует в нужном формате нужные данные.
Создаем скрипт.
Для скрипта я выбрал powershell. Его я знаю немного лучше других скриптовых языков, да и учитывая, что все будет крутиться во круг WMI, сделать его можно было бы и на VBS.
Итак, скрипт.
Задача скрипта состоит в том, чтобы определить число логических процессоров с помощью WMI и вывести в консоль эти данные в формате JSON. Передавать мы будем переменную с именем {#PROCNUM}, а также ее значения. Формат вывода будет примерно таким, в зависимости от количества логических процессоров:
{
"data":[
{ "{#PROCNUM}":"0"},
{ "{#PROCNUM}":"1"},
{ "{#PROCNUM}":"2"},
{ "{#PROCNUM}":"3"},
{ "{#PROCNUM}":"4"},
{ "{#PROCNUM}":"5"},
{ "{#PROCNUM}":"6"},
{ "{#PROCNUM}":"7"},
{ "{#PROCNUM}":"8"},
{ "{#PROCNUM}":"9"},
{ "{#PROCNUM}":"10"},
{ "{#PROCNUM}":"11"}
]
}
Скрипт формирования данных
Сам скрипт выглядит так:
$items = Get-WmiObject Win32_PerfFormattedData_PerfOS_Processor | select name |where-object {$_.name -ne '_Total'}
write-host "{"
write-host " `"data`":["
write-host
foreach ($objItem in $Items) {
$line = " { `"{#PROCNUM}`":`"" + $objItem.Name + "`"},"
write-host $line
}
write-host
write-host " ]"
write-host "}"
write-host
Сейчас мы получаем, что при запуске скрипта он узнает сколько ядер и формирует пакет для отправки.
Что же мы делаем дальше? Нужно создать Discovery rule.
Добавялем низкоуровневое обнаружение в настройках zabbix сервера
Для этого заходим в нужный шаблон, который добавлен к интересующим нас хостам, в раздел Discovery и нажимаем кнопку Create discovery rule.
Тут мы видим непонятное значение поля key: PSScript[proc.ps1]. Это UserParameter. Этот пункт создан для удобства, теперь в каждом новом объекте мы можем просто вписывать параметр в виде имени PS скрипта и он будет искать его в заранее оговоренном месте. Сам параметр прописывается в файле конфигурации клиента (обычно называется zabbix_agentd.conf) и выглядит так:
UserParameter=PSScript[*],powershell -File "C:Program Fileszabbix agentscript$1"
Мы создали новое правило обнаружения с пользовательским сбором данных. Запрос на изменение информации задан как 1 час. Пожалуй, для таких статических данных, как количество процессоров, это слишком часто :), но каждый волен поставить свое значение. Для первоначального сбора данных и отладки лучше это значение уменьшить до совсем небольших значений, чтобы не ждать часами выполнение скрипта.
Настройка прототипов данных
Хорошо. Данные о количестве процессоров мы начали собирать. Но в результате нам нужны не эти данные, а новый item в мониторинге. Именно item может собирать данные, а не наш скрипт, наш скрипт служит только для обнаружения самих элементов для сбора данных.
А для того что бы создать новый элемент сбора данных, полученный на основании LLD, в том же разделе Discovery мы создаем новый прототип. Для этого заходим в item prototypes и нажимаем create item prototype. Я создал вот такой элемент сбора:
Для сбора данных используется стандартный счетчик производительности. В zabbix для сбора этих данных есть ключ perf_counter. Вместо номера логического ядра мы вставляем полученное значение в виде переменной из раздела Discovery.
Теперь все готово. Или почти все…
С этого момента, когда скрипт discovery обнаружит логические процессоры, для этого хоста будут созданы элементы сбора данных созданных точно для этого количества процессоров.
И теперь если мы зайдем в items для хоста, низкоуровневое обнаружение для которого уже отработало, то мы увидим, что появились новые элементы:
Эти элементы нельзя удалить стандартным способом, т.к. они созданы автоматически, они выделены особенным префиксом с названием правила низкоуровневого обнаружения. На скриншоте кажется, что написана какая-то фигня в имени :), на самом деле все просто, я использую трехзначный код в каждом имени для сортировки. То есть 100 это только лишь сортировочный номер. Следующая цифра от 0 до 11 это номер логического процессора. А дальше уже «% загруженности процессора». А то сначала может показаться, что это 0% загруженности процессора и я пытаюсь это значение собрать
Единственный недостаток всего этого метода в том, что график, такой как в заголовке этого поста, нельзя создать с помощью механизма низкоуровневого обнаружения. То есть мы можем, конечно, создать не только item, но и graph объект для каждого логического процессора, но создать один суммарный график автоматически со всеми обнаруженными логическими процессорами не получится. По крайней мере я не видел как это можно было бы сделать, на форуме zabbix мне также не смогли подсказать. Это, конечно, не особенно серьезный недостаток, но если у вас 200 хостов, это может стать проблемой :). Ведь график для каждого хоста нужно будет создавать вручную.
Мониторим производительность каждого физического диска в системе
В вышеприведённом способе лучше разобраться и тогда это открывает достаточно широкие возможности для мониторинга объектов в системе, количество которых либо отличается от хоста к хосту либо их количество во все изменяется во время работы.
Например, часто случается, что нужно определить, не происходил ли недостаток в ресурсах физического диска, установленного в сервере. Чаще всего эти данные сложно уловить в реалтайме и хочется иметь их собранными постфактум. Для этого я ввел аналогичное обнаружение и для физических дисков для сбора обширной статистики по ним. И, в отличии от процессоров, элементов сбора данных я создал их с избытком.
Тут, конечно, надо быть внимательным и если mysql у вас стоит на каком-нибудь стареньком забитом компе, то подобное количество достаточно быстро унесет вашу базу данных в небеса. Т.к. в приведенном примере для каждого хоста создается для каждого физического диска 20 новых элементов, которые будут создавать одного новое значение в минуту. В масштабе пары десятков серверов с кучами разных дисков это выливается в более-менее весомое количество данных. Но тут каждый волен выбирать свой путь самурая
Скрипт для LLD физических дисков выглядит так:
$items = Get-WmiObject Win32_PerfRawData_PerfDisk_PhysicalDisk | select name |where-object {$_.name -ne '_Total'}
write-host "{"
write-host " `"data`":["
write-host
foreach ($objItem in $Items) {
$line = " { `"{#DISKNUM}`":`"" + $objItem.Name + "`"},"
write-host $line
}
write-host
write-host " ]"
write-host "}"
write-host
Добавляем новое правило обнаружения по аналогии с CPU. Точно также мы создаем нужные элементы в discovery.
Вообще, конечно, этот механизм дает довольно большие возможности по определению различных элементов для мониторинга. Таким же способом можно, например, добавить мониторинг сетевых интерфейсов, процессов в системе, служб и любых других элементов, имя которых и количество заранее неизвестно.
Надеюсь эта статья кому-нибудь поможет разобраться с LLD. С удовольствием отвечу на возникшие вопросы.
Приведу пример мониторинга использования каждого ядра процессора используя Zabbix.
Допустим на высоконагруженном NAT сервере основная нагрузка от softirq, присутствует один процессор с 8 ядрами, а также на сервере установлен Zabbix агент.
И чтобы увидеть равномерно ли распределены прерывания сетевого адаптера по ядрам процессора, создадим элементы данных на Zabbix сервере, в которых укажем:
Тип: Zabbix агент
Тип информации: Числовой (с плавающей точкой)
Единица измерения: %
А также ключ:
system.cpu.util[0,softirq,avg5]
Где 0 — номер процессора, softirq — тип нагрузки, avg5 — средняя нагрузка за 5 минут. Аналогично создадим элементы данных для других ядер процессора с ключами, а также добавим их на один график:
system.cpu.util[1,softirq,avg5] system.cpu.util[2,softirq,avg5] system.cpu.util[3,softirq,avg5] ...
Вместо softirq можно указать idle, nice, user (по умолчанию для Linux), system (по умолчанию для Windows), iowait, interrupt, softirq, steal, guest, guest_nice.
А вместо avg5 можно указать: avg1 (среднее за одну минуту, по умолчанию) или avg15 (среднее за 15 минут).

Чтобы не указывать ядра процессоров вручную, можно создать правило обнаружения:
И указать в нем элемент данных, например:
system.cpu.util[{#CPU.NUMBER},softirq,avg5]
Также можно создать триггер, чтобы узнать когда значение будет больше 90:
({ixnfo.com cpu template:system.cpu.util[0,softirq,avg5].last(0)}>90)
Ниже приведу примеры элементов данных, которые отображают различную информацию о CPU, кстати эти элементы данных по умолчанию присутствуют в шаблоне «Template OS Linux».
Processor load (1 min average per core):
system.cpu.load[percpu,avg1]
Processor load (5 min average per core):
system.cpu.load[percpu,avg5]
Processor load (15 min average per core):
system.cpu.load[percpu,avg15]
Interrupts per second:
Context switches per second:
CPU idle time:
CPU interrupt time:
system.cpu.util[,interrupt]
CPU iowait time:
CPU nice time:
CPU softirq time:
system.cpu.util[,softirq]
CPU steal time:
CPU system time:
CPU user time:
Смотрите другие мои статьи в категории Zabbix.
После создания элемента мониторинга создайте новый триггер, вы можете проверить, полезен ли триггер в конструкторе выражений
Выражение: {Загрузка ЦП Windows в шаблоне: perf_counter [ Processor (_Total) % времени процессора] .avg (5m)}> 80
После создания триггера добавьте график для просмотра графика использования процессора
После того, как добавление прошло успешно, вы можете просмотреть графическую таблицу CPU, и данные указывают на успешный мониторинг!
▼Примечание. Этот шаблон ввода-вывода собирает данные ввода-вывода всех физических жестких дисков всего сервера.
Например: сервер имеет твердотельный жесткий диск, механический жесткий диск, он твердотельный жесткий диск и данные механического жесткого диска отображаются вместе
При мониторинге сервера базы данных лучше всего рассматривать твердотельный диск и механический жесткий диск отдельно, используя разные пороги срабатывания.
Поскольку все жесткие диски на машине сложены вместе, очень трудно отличить триггер от твердотельного диска и механического жесткого диска
Адрес загрузки шаблона: https://files.cnblogs.com/files/Sungeek/Windows%E7%9B%91%E6%8E%A7%E7%A3%81%E7%9B%98IO.xml

4. Мониторинг Windows — изменение порога срабатывания диска
Выберите Конфигурация —> Шаблон —> (Шаблон ОС Linux / Шаблон ОС Windows)
Я здесь для мониторинга Windows, поэтому измените шаблон Windows, если вы отслеживаете Linux, вы можете изменить шаблон Linux
По умолчанию обновляется один раз в час, и изменяется до 600 секунд, то есть обновляется каждые 10 минут. Через 10 минут вы можете видеть значения мониторинга сетевой карты и диска!


Выберите конфигурацию —> шаблон —> (Шаблон ОС Linux / Шаблон ОС Windows) —> Обнаружение подключенной файловой системы —> Тип триггера
Я уже модифицировал его здесь. Если нет изменений или нет элемента триггера, вы можете нажать в правом верхнем углу (создать прототип триггера)
Имя: на диске {#FSNAME} свободное место на диске менее 50 ГБ.
Выражение: {Шаблон ОС Windows: vfs.fs.size [{# FSNAME}, бесплатно] .last (0)} <50000000000


Выберите конфигурацию —> шаблон —> (Шаблон ОС Linux / Шаблон ОС Windows) —> Обнаружение подключенной файловой системы —> Тип элемента мониторинга
Моя сторона была изменена. Если нет изменений или этот элемент мониторинга недоступен, вы можете нажать в правом верхнем углу (создать прототип элемента мониторинга)
Название: Свободное место на диске на $ 1
Выражение: vfs.fs.size [{# FSNAME}, бесплатно]
Единица измерения: B
Интервал обновления: 1 м или 60 с

5. Мониторинг правил автоматического обнаружения Windows-сетевой карты
Описание проблемы: Это шаблон Windows по умолчанию, который содержит сетевую карту сервера автообнаружения, но он автоматически найдет много других сетевых карт и другую графику.
Решение: Бесполезно удалять соответствующий графический объект напрямую, поскольку правило автоматического обнаружения будет снова автоматически обнаружено, поэтому вам необходимо изменить правило
1. Внутри правил автообнаружения —-> Обнаружение службы Windows (это можно отключить)
2. Управление —> Общее —> Регулярные выражения —> Сетевые интерфейсы для обнаружения (добавьте параметры ниже, чтобы сетевая карта не была автоматически обнаружена с этими параметрами)
1 »Microsoft [Результат неверный] 2 »Тередо [Результат ложный] 3 »Qos [результат ложный] 4 »ВПП [Результат неверный] 5 »RAS [Результат ложный] 6 »WAN [результат ложный] 7 » ^Nu[0-9.]*$ [Результат ложный] 8 » ^[Ss] ystem $ [Результат ложный] 9 » ^[Ll]o[0-9.]*$ [Результат ложный] 10 » ^NULL[0-9.]*$ [Результат ложный] 11 » ^(In)?[Ll]oop[Bb]ack[0-9._]*$ [Результат ложный] 12 » ^Программный интерфейс Loopback [результат ложный] 13 »Сетевой трафик в Broadcom NetXtreme Gigabit Ethernet [Результат неверен]


6. Настройте функцию почтовой тревоги на сервере
Я использую корпоративную электронную почту Tencent
Как показано на рисунке ниже, Management —> Alarm Media Type —> Email
Следует отметить, что в качестве имени пользователя следует указать свою служебную электронную почту, пароль ввести пароль
Сначала я подумал, что это имя электронной почты, поэтому я не мог его отправить, я мог использовать свой почтовый ящик QQ
SMTP-сервер: smtp.exmail.qq.com
Порт: 465
SMTP электронная почта: [email protected]
Имя пользователя: [email protected]

Конфигурация —> Действие —> Триггер
Создать триггер для отправки оповещений по электронной почте

Операция:
Заголовок по умолчанию: сбой {TRIGGER.STATUS}, сервер: {HOSTNAME1}: сбой {TRIGGER.NAME}!
Содержание сообщения:
Хост тревоги: {HOSTNAME1}
Время будильника: {EVENT.DATE} {EVENT.TIME}
Уровень тревоги: {TRIGGER.NAME}
Элемент тревоги: {TRIGGER.KEY1}
Подробности вопроса: {ITEM.NAME}: {ITEM.VALUE}
Текущий статус: {TRIGGER.STATUS}: {ITEM.VALUE1}
Идентификатор события: {ENET.ID}
Операция восстановления:
Заголовок по умолчанию: Восстановить {TRIGGER.STATUS}, Сервер: {HOSTNAME1}: {TRIGGER.NAME} восстановлен!
Содержание сообщения:
Хост тревоги: {HOSTNAME1}
Время будильника: {EVENT.DATE} {EVENT.TIME}
Уровень тревоги: {TRIGGER.NAME}
Элемент тревоги: {TRIGGER.KEY1}
Подробности вопроса: {ITEM.NAME}: {ITEM.VALUE}
Текущий статус: {TRIGGER.STATUS}: {ITEM.VALUE1}
Идентификатор события: {ENET.ID}
Подтвердите операцию:
Название по умолчанию: Подтверждено: {TRIGGER.NAME}
Содержание сообщения:
{USER.FULLNAME} подтвердил проблему {ACK.DATE} {ACK.TIME} следующее сообщение:
{ACK.MESSAGE}
Текущее состояние проблемы: {EVENT.STATUS}

Наконец, настройте среду тревоги, то есть, чтобы активировать условие тревоги, вам нужно отправить электронное письмо, чтобы узнать, какой почтовый ящик
Нажмите на маленький аватар, затем введите основную информацию пользователя, выберите медиа-сигнал тревоги, чтобы установить
Вы можете выбрать уровень серьезности самостоятельно. После того, как настройка включена, функция будильника установлена!


I am new in Zabbix and I am using Zabbix 3.4 version. I have installed server on Linux and want to monitor and check status of Windows service using its Windows agent.
I got the status of services using the key below
service.info[<serviceName>,state]
It returns me proper status of service. Now I want to check how much CPU is utilized by process and how much memory is utilized by process.
I tried some of keys but it’s not returning proper value.
perf_counter[Process(<processName>)% User Time] // to get CPU utilization by process
proc_info[<processName>,wkset] // to get memory utilize by process
system.cpu.util[,system,avg5] // to get total CPU utilization
vm.memory.size[available] // to get total RAM utilization
But none of above working properly. I tried other keys also but agent logs say it’s unsupported. I checked forum and searched on Google but nothing found.
![]()
Richlv
3,8621 gold badge16 silver badges20 bronze badges
asked Feb 5, 2018 at 11:22
![]()
Usually there isn’t a direct match Windows Service -> Specific process.
Any service spawns N processes for its internals and also can spawn additional processes to manage incoming connection, log requests and so on.
Think about a classic httpd server: you should find at least one master process, various pre-forked server processes and php/php-fpm processes for current requests.
Regarding the keys you provided, what do you mean by «not working properly» ?
You can refer to Zabbix documentation for Windows-specific items for the exact syntax of the items and the meaning of the return values.
answered Feb 10, 2018 at 22:22
![]()
Simone ZabberoniSimone Zabberoni
1,9831 gold badge9 silver badges15 bronze badges
You can use Zabbix item for CPU Utilization of average 5 min:
system.cpu.util[,,avg5]
This will give you average usage of CPU per 5 mins on Windows server. You can then create an appropriate trigger for the same.
![]()
tuomastik
4,3915 gold badges35 silver badges47 bronze badges
answered Feb 11, 2019 at 13:29
![]()
itmavenitmaven
811 silver badge3 bronze badges