Обзор
Некоторые приложения (особенно тех, которые являются веб-) приходится иметь дело с данными в Юникоде, закодированные с помощью метода кодировки UTF-8. SQL Server 7.0 и SQL Server 2000 используйте другую кодировку Юникод (UCS-2) и не распознают как данные символы UTF-8. В этой статье обсуждаются некоторые параметры в этом случае.
Дополнительные сведения
Данные в формате Юникод могут кодироваться различными способами. UTF-8 и UCS-2, два стандартных способа хранения битовую маску, представляющую символов Юникода. Microsoft Windows NT, SQL Server, Java, COM и драйвер ODBC для SQL Server и поставщик OLEDB все внутренне представления данных в формате Юникод в качестве UCS-2.
Параметры для использования SQL Server 7.0 или SQL Server 2000 в качестве сервера базы данных для приложения, которое отправляет и получает данные Юникода в кодировке UTF-8:
-
Если приложение использует ASP (ASP) и с помощью Internet Information Server (IIS) 5.0 и Microsoft Windows 2000, можно добавить серверный сценарий ASP «< % Session.Codepage=65001% >». Это заставляет IIS для преобразования всех динамически создаваемых строк (пример: Response.Write) из UCS-2, UTF-8, автоматически перед их отправкой клиенту.
Если вы не хотите включить сеансы, также можно использовать серверную директиву «< % @ кодовая страница 65001% = >».
Все данные UTF-8, отправляемых от клиента к серверу через GET или POST также преобразуется в UCS-2 автоматически. Свойство Session.Codepage является рекомендуется обрабатывать данные UTF-8 в веб-приложении. Этот параметр кодовая страница недоступна на сервере IIS 4.0 и Windows NT 4.0. Дополнительные сведения см. ниже статьи базы знаний Майкрософт:
254313 сообщение об ошибке: ошибка ASP «ASP 0203′ недопустимый код
-
Перевод в и из UCS-2 или UTF-8 в зависимости от приложения. Образец кода для этого типа, преобразования можно найти на веб-узле консорциума Юникода:
ftp://ftp.unicode.org/Public/PROGRAMS/CVTUTF/Подробное описание алгоритма для преобразования UCS-2, UTF-8 можно найти в документе RFC2279 запроса Интернета для комментариев.
В Windows NT или Windows 2000, можно использовать функции Win32 MultiByteToWideChar и WideCharToMultiByte для преобразования UTF-8 в UCS-2, передав константы CP_UTF8 (65001) как первый параметр для функции.
-
Изменение приложения для использования UCS-2 вместо кодировки UTF-8.
-
Хранить данные UTF-8 на сервере с помощью столбцов двоичного файла, ГРАФИЧЕСКИЕ и VARBINARY. Хранение данных в кодировке UTF-8 на SQL Server означает, что SQL Server нельзя использовать для сортировки и поиска диапазонов значений, таких как, если данные были допустимыми символьных данных. Типы операций на столбцы, содержащие данные UTF-8, не будет возвращать ожидаемые результаты включают «ORDER BY», больше-чем «>» и меньше-чем «<» сравнение и встроенные функции обработки строк SQL Server как SUBSTRING().
Тем не менее сравнения на равенство, будет работать до тех пор, пока на уровне байтов сравниваемые строки эквивалентны. Обратите внимание, что при сохранении данных в кодировке UTF-8 в SQL Server не следует использовать, символьных столбцов (CHAR, NCHAR/VARCHAR и т. д.). UTF-8 не является допустимой символьных данных для SQL Server, а также путем хранения несимвольных данных в символьных столбцов, существует риск возникновения проблемы, например вопросы, описанные в следующих статьях базы знаний Майкрософт:
155723 INF: SQL Server усечение строки DBCS
234748 PRB: драйвер ODBC SQL Server преобразует события языка в Юникод
При использовании этого параметра следует помнить, что в дальнейшем для доступа к данным UTF-8, хранящиеся внутри SQL Server из любого приложения, веб-обозреватель (например, из приложения без веб интерфейса ODBC) необходимо будет выполнить преобразование из UTF-8 в UCS-2 в этом приложении как ODBC, OLEDB, COM, вызовы Win32 API, VB и C во время выполнения функции обработки строк не работают с данных в кодировке UTF-8. Оно перемещает нагрузку перевод в другое приложение. -
Если требования к отсутствует необходимость хранения данных из комбинации языков, которые не могут быть удовлетворены одну кодовую страницу, не требуется использовать Юникод.
В SQL Server, начиная с SQL Server 7.0 была введена поддержка Юникода. Поскольку SQL Server 6.5 не поддерживает хранение данных в формате Юникод, для SQL Server 6.5 только те параметры описаны в шаги 4 и 5.
Нужна дополнительная помощь?
January 5, 2013
Posted by:
gaHcep
Category:
MySQL, Unicode
Сегодня речь пойдет о MySQL и о настройке UTF8 кодировки по-умолчанию.
Тема заезжена, но как я убедился за прошедшую неделю, мало кто в состоянии нормально пояснить какие параметры и куда надо прописать для полноценной работы с UTF8 в MySQL. К сожалению, ситуация на тематических блогах оставляет желать лучшего. Основной тип ответа — приведение соедржимого конфигурационного файла с комментарием типа “попробуй, у меня это работает”.
Основная цель данного поста — выяснить, какие параметры и с какими значениями следует прописать в конфигурационный файл my.cnf (my.ini) для дальнейшей беспроблемной работы с Юникодом.
Рабочее окружение
UTF8 на данный момент у меня успешно работает в Мастер-Слейв конфигурации:
- MySQL версии 5.1.66
- Два сервера CentOS версии 6.3
- Репликация между серверами Master-Slave на базе SSL
Любой внешний клиент в состоянии корректно работать с UTF8 базой (проверено на EMS Manager for MySQL c Windows 8 x64).
Все опции и настройки я привожу для версии сервера 5.1.x, однако с минимальными (а то и вовсе без оных) изменениями все это будет работать и на версиях 5.5.x и 5.6.x.
Параметры кодировок MySQL
Довольно часто приходится видеть в ответах на вопросы о настройке UTF8 следующее:
[mysqld]
init_connect='SET collation_connection = utf8_general_ci'
init_connect='SET NAMES utf8'
default-character-set=utf8
character-set-server=utf8
collation-server=utf8_general_ci
skip-character-set-client-handshake
Предполагается, что после вставки всего этого добра (тут кстати есть противоречащие друг другу опции) в конфигурационный файл my.cnf (my.ini) магический Юникод начнет работать.
Но давайте забудем о списке и попытаемся разбираться со всеми опциями сами и начнем с самого начала. То есть с документации. Потому как все это прекрасно описано в документации MySQL на официальном сайте. Я лишь постараюсь последовательно рассказать о параметрах сервера и прояснить неясные моменты.
Главный раздел по описанию кодировок (character sets) и их представлений (collations — используется например при сортировке) в контексте сервера, базы, таблиц — это секция 10.1.3. Specifying Character Sets and Collations.
Символьная кодировка может быть задана для:
- сервера,
- базы данных,
- таблицы и
- колонок в таблице.
Сделано это для гибкой настройки баз данных и доступа клиентов с разными кодировками. Однако, последнее не входит в область рассмотрения данного поста, поэтому будем рассматривать вариант с кодировкой UTF8 настроенной для всего по-умолчанию.
Все параметры могут быть переданы серверу тремя разными способами:
- через командную строку mysqld
- через конфигурационный файл my.cnf (my.ini)
- через опции компиляции.
Второй и третий варианты рассматриваться не будут. Тут уместно будет просто прочитать официальные доки — в каждом разделе приведены примеры конфигурации с использованием всех трех способов. Я же буду использовать первый вариант.
Кодировка (character set) и представление (collation) сервера
Секция 10.1.3.1. Server Character Set and Collation
Кодировка (characher set) — набор используемых символов.
Представление (collation) — набор правил для сравнения символов в наборе.
Тут есть несколько фундаментальных вещей которые надо понимать.
Основные параметры используемые в контексте сервера — это character_set_server и collation_server. Оба параметра влияют на определение кодировки и отображения сервера MySQL.
Можно задать оба параметра либо только один из них. При этом важно знать как задача того или иного влияет на определение отсутствующего:
-
Не заданы — используются значения по умолчанию (дефолтные),
-
Заданы оба — используются указанные кодировка и ее представление,
-
Задана только кодировка — ее представление выставляется по умолчанию для данного типа кодировки. Что это значит? Для каждого типа кодировки есть ее дефолтное представление, например, дефолтная кодировка сервера —
latin1, а дефолтное отображение для нее —latin1_swedish_ci.
Посмотреть соответствие кодировки и ее дефолтного представления можно используя команду:SHOW COLLATION LIKE ‘your_character_set_name’;
Пример:
mysql> SHOW COLLATION LIKE ‘latin1%’;
+-------------------+---------+----+---------+----------+---------+ | Collation | Charset | Id | Default | Compiled | Sortlen | +-------------------+---------+----+---------+----------+---------+ | latin1_german1_ci | latin1 | 5 | | Yes | 1 | | latin1_swedish_ci | latin1 | 8 | Yes | Yes | 1 | | latin1_danish_ci | latin1 | 15 | | Yes | 1 | | latin1_german2_ci | latin1 | 31 | | Yes | 2 | | latin1_bin | latin1 | 47 | | Yes | 1 | | latin1_general_ci | latin1 | 48 | | Yes | 1 | | latin1_general_cs | latin1 | 49 | | Yes | 1 | | latin1_spanish_ci | latin1 | 94 | | Yes | 1 | +-------------------+---------+----+---------+----------+---------+
Поле Default дает ответ о представлении выбранной кодировки.
В нашем случае, при настройке дефолтной кодировки в UTF8, параметры должны быть определены, так как могут быть использованы при определении кодировки или представления базы данных:
Наши команды:
my.cnf (my.ini)
[mysqld]
character-set-server = utf8
collation-server = utf8_unicode_ci
Дефолтное представление для utf8 — utf8_general_ci, так что если бы мы его использовали вместо utf8_unicode_ci, то параметр collation_server можно было бы вообще опустить.
Кодировка (character set) и представление (collation) базы данных
Секция 10.1.3.2. Database Character Set and Collation
Секция 10.1.4. Connection Character Sets and Collations
Тут есть два варианта определения кодировки и представления:
-
явно — при выполнении запроса на создание базы данных:
CREATE DATABASE db_name CHARACTER SET latin1 COLLATE latin1_swedish_ci;
-
неявно через переменные
character_set_databaseиcollation_database.
Однако, эти переменные нельзя задать явно ни в командной строке ни в конфигурационном файле. Как они инициализируются — чуть ниже.
Вообще при работе с базой данных огромную роль помимо серверных настроек играют настройки клиент-серверного соединения (connection). На этом этапе вступают в игру следующие специфичные для соединения параметры:
character_set_client— кодировка в которой посылается запрос от клиентаcharacter_set_connection— кодировка используемая для конвертации пришедшего запроса (statement’а)character_set_results— кодировку, в которую сервер должен перевести результат перед его отправкой клиенту
Есть еще представление кодировки соединения (colation_connection). Для чего нужен этот параметр думаю пояснять не надо.
Озадачиваться проблемой инициализации всех этих переменных не стоит (хотя в нашем случае присвоить им значения необходимо).
Есть способ проще: существует два типа запросов (statements) которые задают настройки соединения клиента с сервером группой:
Запрос SET NAMES ‘charset_name’ [COLLATE ‘collation_name’]
Параметр определяет в какой кодировке теперь будут приходить сообщения для сервера от клиента. Прелесть в том, что запрос SET NAMES x эквивалентен следующей группе:
SET character_set_client = x;
SET character_set_results = x;
SET character_set_connection = x;
Для определении представления кодировки соединения (colation_connection) отличного от дефолтного, следует дополнить запрос:
SET NAMES x COLLATE y
А так как у нас utf8 и ее дефолтное представление utf8_general_ci, то нам нужно выпонить полный запрос:
SET NAMES utf8 COLLATE utf8_unicode_ci
Таким образом, используя только этот запрос, можно добиться корректной UTF8 инициализации соединения.
Однако, тут есть один нюанс:
SET NAMES x, как понятно из определения, определяет настройку клиента при коннекте к серверу. Но что делать, если клиент — сам mysql.exe и нам хочется установить collation_connection по-умолчанию, не выполняя каждый раз SET NAMES x при коннекте?
Для этих целей, существует еще один параметр — default_character_set.
Он эквивалентен запросу SET NAMES utf8. В случае его использования задать collation_connection отличный от дефолтного уже не получится, поэтому придется заюзать еще одну команду init_connect (так как напрямую collation_connection нельзя прописать в конфигурационном файле):
init_connect=‘SET collation_connection = utf8_unicode_ci’
Но и тут есть еще одно но: init_connect команда не выполняется для SUPER пользователей — пользователей, обладающих привилегией SUPER. root входит в этот перечень, поэтому при коннекте root’ом команду SET collation_connection = utf8_unicode_ci все же придется выполнить вручную.
Запрос SET CHARACTER SET charset_name
Запрос групповой и он также эквивалентен следующей группе:
SET character_set_client = x;
SET character_set_results = x;
SET collation_connection = @@collation_database;
Согласно документации, разница между двумя запросами в том, что параметры character_set_connection и collation_connection будут установлены на @@character_set_database и @@collation_database соответственно (выше я про них упоминал).
За более детальной информацией отсылаю по двум источникам — собственно к официальной документации и прекрасно оформленному ответу на stackoverflow.com.
Для нашей задачи вполне хватает первого параметра вместе с дополнительной командой.
Подытожим: различные сценарии и что юзается на каждом из них — относительно к настройкам соединения:
- Если к базе коннектится mysql.exe клиент с пользователем с привилегией SUPER:
- срабатывает опция в конфигурационном файле
default_character_set = utf8 - надо выполнить вручную команду
init_connect='SET collation_connection = utf8_unicode_ci'
- срабатывает опция в конфигурационном файле
- Если к базе коннектится mysql.exe клиент с пользователем без привилегии SUPER:
- срабатывает опция в конфигурационном файле
default_character_set = utf8 - срабатывает команда в конфигурационном файле
init_connect='SET collation_connection = utf8_unicode_ci'
- срабатывает опция в конфигурационном файле
- Если к базе коннектится внешний клиент:
- надо выполнить вручную команду
SET NAMES utf8 COLLATE utf8_unicode_ci
- надо выполнить вручную команду
Наши команды:
my.cnf (my.ini)
[client]
default_character_set = utf8[mysqld]
init_connect=‘SET collation_connection = utf8_unicode_ci’
Кодировка (character set) и представление (collation) таблиц
Секция 10.1.3.3. Table Character Set and Collation
Тут все довольно просто. Задать кодировку и ее представление можно через команды:
CREATE TABLE t1 ( … )
CHARACTER SET utf8 COLLATE utf8_unicode_ci;
Тут главное иметь в виду, что если эти настройки не заданы, то берутся настройки базы данных (см. пред. раздел). Нам эти настройки не интересны.
Кодировка (character set) и представление (collation) колонок в таблице
Секция 10.1.3.4. Column Character Set and Collation
Тут по аналогии с пред. секцией. Если параметры кодировок не указаны, берутся те, что указывались для таблицы.
Прежде чем перейти к след. разделу, должен сказать, что все команды и запросы относятся к указанной версии MySQL и в случае возникновения каких-либо проблем советую обратиться к соответствующей версии документации.
skip-character-set-client-handshake
Помимо освещенных параметров, есть еще один довольно часто фигурирующий в разного рода источниках — skip-character-set-client-handshake. Установка этого параметра позволит проигнорировать информацию клиента о кодировке. Я данный параметр не использовал.
Верификация настроек
Итак, вот финальный snapshot наших изменений в файле my.cnf (my.ini):
[mysqld]
init_connect=‘SET collation_connection = utf8_unicode_ci’
character-set-server = utf8
collation-server = utf8_unicode_ci[client]
default-character-set = utf8
После применения всех опций и рестарта сервера mysql для проверки настроек можно воспользоваться командами SHOW VARIABLES LIKE 'char%' и SHOW VARIABLES LIKE 'collation%';
Состояние среды до изменений:
mysql> SHOW VARIABLES LIKE'character%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | latin1 |
| character_set_connection | latin1 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | latin1 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
mysql> SHOW VARIABLES LIKE 'collation%';
+----------------------+-------------------+
| Variable_name | Value |
+----------------------+-------------------+
| collation_connection | latin1_swedish_ci |
| collation_database | latin1_swedish_ci |
| collation_server | latin1_swedish_ci |
+----------------------+-------------------+
Состояние среды после изменений (в случае, если вы приконнектились не SUPER пользователем):
mysql> SHOW VARIABLES LIKE 'character%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
mysql> SHOW VARIABLES LIKE 'collation%';
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | utf8_unicode_ci |
| collation_database | utf8_unicode_ci |
| collation_server | utf8_unicode_ci |
+----------------------+-----------------+
Для примера, вот отличие при соединении через mysql.exe пользователем с и без привилегии SUPER:
с привилегией:
mysql> SHOW VARIABLES LIKE 'collation%';
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | **utf8_general_ci** |
| collation_database | utf8_unicode_ci |
| collation_server | utf8_unicode_ci |
+----------------------+-----------------+
с привилегией и выполненной вручную командой ‘SET collation_connection = utf8_unicode_ci’:
mysql> SHOW VARIABLES LIKE 'collation%';
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | utf8_unicode_ci |
| collation_database | utf8_unicode_ci |
| collation_server | utf8_unicode_ci |
+----------------------+-----------------+
без привилегии:
mysql> SHOW VARIABLES LIKE 'collation%';
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | utf8_unicode_ci |
| collation_database | utf8_unicode_ci |
| collation_server | utf8_unicode_ci |
+----------------------+-----------------+
Поздравляю, теперь ваши база, таблицы и все в таблицах по-умолчанию в кодировке UTF8.
Ссылки
- Официальное руководство MySQL версии 5.1
- Отличие utf8_unicode_ci от utf8_general_ci
- “MySQL Character Set Support” на informit.com позволит вам больше узнать о том что есть characher set и collation.
« Previous Blog Post | Back to top | Next Blog Post »
comments powered by Disqus
За последние 24 часа нас посетил 9391 программист и 1201 робот. Сейчас ищут 334 программиста …
Проблема с кодировкой. Вместо русских букв кракозябры.
Тема в разделе «MySQL», создана пользователем Sergey89, 30 янв 2008.
Страница 1 из 3
-

Sergey89
Активный пользователь- С нами с:
- 4 янв 2007
- Сообщения:
- 4.796
- Симпатии:
- 0
Данная «проблема» ждёт пользователей MySQL версии 4.1 и выше, которые никогда не пытались читать документацию.
Первым делом нужно проверить, что установлено нужное сопоставление (collation) для текстовых полей в таблице. Именно в установленной кодировке хранятся данные. Если для полей выставлена «неправильная» кодировка, то измените её. В phpMyAdmin это можно сделать при редактировании столбца таблицы, выбрав нужное значение из списка Сравнений. Для русский символов это может быть, например, cp1251_general_ci (основная регистронезависимая cp1251). Для UTF-8 — utf8_general_ci.
Теперь нужно выставить кодировку соединения с сервером. В MySQL есть выражение SET NAMES, предназначенное специально для этого:
[sql]SET NAMES ‘cp1251’;[/sql]
Выполнить данный запрос нужно сразу после подключения к серверу.После этого все данные будут приходить в установленной кодировке. Кодировку соединения можно менять:
[sql]SET NAMES ‘utf8’;[/sql]
В этом случае данные будут приходить в UTF-8, никак не затрагивая данные в таблице, которые могут храниться в другой кодировке. Следите за тем, чтобы весь остальной текст на странице тоже был в UTF-8.Вопросы? Замечания?
-
M@rko
Активный пользователь- С нами с:
- 21 янв 2008
- Сообщения:
- 5
- Симпатии:
- 0
пробовал.
все равно ведает кроказяблы! хоть и другие… -
Sergey89
Активный пользователь- С нами с:
- 4 янв 2007
- Сообщения:
- 4.796
- Симпатии:
- 0
Предлагаешь мне погадать? В какой кодировке таблица, в какой кодировке страница? Юзер рутовый или нет?
-
Команда форума
МодераторДобавлю к сообщения Сергея:
Сегодня была фигня, что русский текст показывался корректно (utf8 и в БД и на странице), но буквы «ш» и «И» показываются в виде квадратиков (в IE) и другими крякозябрами в других браузерах. Погуглив, решил проблему так:На БД и таблицы установил utf8_general_ci
После коннекта к БД:
[sql]
mysql_query(«SET NAMES ‘utf8’;»);
mysql_query(«SET CHARACTER SET ‘utf8’;»);
mysql_query(«SET SESSION collation_connection = ‘utf8_general_ci’;»);
[/sql]И все нормально работает.
-
tmanager
Активный пользователь- С нами с:
- 12 мар 2008
- Сообщения:
- 108
- Симпатии:
- 0
Стоит добавить, как поддержка кодировки уcтанавливается на MySQL под Windows
Пример конфигурационного файла my.ini
[client]
port = 3306#Конфигурационные параметры для сервера MySQL
[mysqld]
port = 3306
socket = /tmp/mysql.sock
skip-locking
key_buffer = 16K
max_allowed_packet = 1M
table_cache = 4
sort_buffer_size = 64K
read_buffer_size = 256K
read_rnd_buffer_size = 256K
net_buffer_length = 2K
thread_stack = 64K
# Установка кириллицы на сервере
default-character-set=cp1251 #Указание кодировки
character-sets-dir=g:/mysql/share/charsets #Указание пути к папке кодировок (скорректируйте для своего сервера!)server-id = 1
# Конфигурационные параметры для программы резервного копирования
[mysqldump]
quick
max_allowed_packet = 16M
# Установка кириллицы
default-character-set=cp1251 #Указание кодировки
character-sets-dir=g:/mysql/share/charsets #Указание пути к папке кодировок (скорректируйте для своего сервера!)# Конфигурационные параметры для программы-клиента mysql.exe
[mysql]
no-auto-rehash
# Установка кириллицы
default-character-set=cp1251 #Указание кодировки
character-sets-dir=g:/mysql/share/charsets #Указание пути к папке кодировок (скорректируйте для своего сервера!)[isamchk]
key_buffer = 8M
sort_buffer_size = 8M[myisamchk]
key_buffer = 8M
sort_buffer_size = 8M[mysqlhotcopy]
interactive-timeout -
Astoret
Активный пользователь- С нами с:
- 28 фев 2008
- Сообщения:
- 9
- Симпатии:
- 0
Спасибо Sergey89, очень помог твой пост. Двое суток бился, иска))
-
Astoret
Вот этот?")
-
Astoret
Активный пользователь- С нами с:
- 28 фев 2008
- Сообщения:
- 9
- Симпатии:
- 0
-
EugeneTM
Активный пользователь- С нами с:
- 19 апр 2008
- Сообщения:
- 85
- Симпатии:
- 0
Возможно окончательная победа в войне с utf8
MySQL
my.cnf или под виндой my.ini:[client]
default-character-set= utf8
[mysql]
default-character-set=utf8
[mysqld]
default-character-set=utf8
В PHP-скрипте
<?php
/* create a connection object which is not connected */
$link = mysqli_init();
/* connect to server */
mysqli_real_connect($link, ‘localhost’, ‘root’, ‘бла-бла-бла’, ‘бла’);/* check connection */
if (mysqli_connect_errno()) {
printf(«Ошибка соединения с БД : %sn», mysqli_connect_error());
exit();
}/* Устанавливаем кодировку для корректного вывода в браузере */
$query = «SET NAMES ‘utf8′»;
if (mysqli_query($link,$query) === TRUE) {
printf(«Кодировка UTF8 успешно установлена.n»);
}
else {
printf(«Ошибка выполнения запроса на установку кодировки UTF8 для вывода в браузере : %sn»,
mysqli_error($link));
exit ();
}/* Устанавливаем кодировку для корректного collation*/
$query = «SET SESSION collation_connection = ‘utf8_general_ci’;»);
if (mysqli_query($link,$query) === TRUE) {
printf(«Collation UTF8 успешно установлен.n»);
}
else {
printf(«Ошибка выполнения запроса на установку collation UTF8 : %sn»,
mysqli_error($link));
exit ();
}/* close connection */
mysqli_close($link);
?>
Если используете библитеку mysql, соотвтственно подкорректировать вызываемые функции.!!!!! Сам PHP-скрипт должен быть в кодировке UTF8
!!!!! Скрипты MySQL должны быть в кодировке UTF8. Для танкистов: Если в notepad создать текстовый файл, набить какой нибудь код. Этот файл будет иметь кодировку cp1251. Если он будет содержать русские символы, то при попытке выполнить его из под mysql будете посланы на ERROR. Один из примитивных вариантов: в MySQL Query Browser создайте новый Script Tab. В него из Clipboard’а вставте ваш текст. Сохраните его как superpuper.SQL, сравните размер с исходным текстовым файлом. Этот скрипт будет нормально выполняться из под mysql при наличии в нем русских символов. Аналогично проверьте PHP-скрипт.
!!!!! Вставка из clipboarda винды в командную строку mysql катит только если текст не содержит русских символов. Винда вставляет cp1251, и соответственноо mysql посылает на ERROR.
Если все это выполнено, нигде никаких упоминаний про cp1251 не нужно.
PS. Имейте в виду — размер VARCHAR при использовании utf8 не должен превышать 64К/3 = 21,33К
-
Не думал, что после того чего уже пережил — напишу сюда, но
Винда, кодировки в базах — юникод, на страничках — utf8, то же и скрипты.
Не пугайтесь, со страничками все хорошо, везде все по русски. Но, решил сегодня воспользоваться консолью мускуловской, не тут то было: ╨Э╨░╤З╨░╤В╨░ вот такие бяки. И сет намес ставил..
Мне кажется что просто сама консоль 1251 по этому и такие карявости. Я не прав? в любом случае, как это победить, или лучше не париться и юзать как раньше майадмин? -
Sergey89
Активный пользователь- С нами с:
- 4 янв 2007
- Сообщения:
- 4.796
- Симпатии:
- 0
-
У меня программа, в которой я php-код редактирую, иногда возмёт да и сохранит файл в однобайтовой кодировке.
Она это может делать автоматически, если все символы в документе принадлежат одной однобайтовой кодировке и нет ни одного символа из другой.Чтобы быть уверенным, вставляю в начало документа комментарий: #юертз ěščřž
Т.е. набор из символов, которые могут быть одновременно только в многобайтовой кодировке.В notpade тоже можно сохранить в utf-8, если при сохранении в окне её выбрать.
-
Помогите мне пожалуйста…. :_(
Пользуюсь консольным клиентом.
Я создал БД:[sql]CREATE DATABASE admins DEFAULT CHARACTER SET cp1251 COLLATE cp1251_general_ci[/sql]
Создал таблицу, внес в нее данные и между каждым действием писал[sql] set names c1251;[/sql]
На самой странице написал:-
<meta http-equiv=Content-Type content=«text/html; charset=windows-1251» />
И всеравно пишутся каракули *WALL*
-
-
тоже из консоли?
У консоли кодировка cp866 -
- С нами с:
- 2 фев 2007
- Сообщения:
- 4.680
- Симпатии:
- 1
- Адрес:
- Минск
вот скажите мне, ну, есть консоль, ну есть шелл-доступ, и что? Теперь только этим и пользоваться? А вот я ленивый и в консоль лезу только в случаях, когда это действительно надо. Люблю тыкать в кнопки и ссылки
LokiFC
set names c1251; достаточно 1 раз прописать. После соединения с бд.
И вполене возможно, что данные твои пишутся нормально. Попробуй отсешь другие варианты.
В какой кодировке сохранён сам файл? Сомневаюсь, что utf-8, но а вдруг?
Потом, в апаче есть такая директива, как AddDefaultCharset. Отвечает за кодировку в которой по умолчанию будут отдаваться серваком файлы. И если стоит utf-8 или другая отличная от WINDOWS-1251, то чихал он на-
<meta http-equiv=Content-Type content=«text/html; charset=windows-1251» />
. Лечится либу правкой конфига апача, либо отправкой перед выводом текста заголовка
-
<? header(‘Content-Type: text/html; charset=CP1251’); ?>
Вот будешь уверен, что таких косяков нет, можно будет гнать на БД и сочинять всякие извращённые способы заполнения.
-
Sergey89
Активный пользователь- С нами с:
- 4 янв 2007
- Сообщения:
- 4.796
- Симпатии:
- 0
Набери в консоли или обрати внимание на то, что
-
2Luge, помогло
Не думал, что проблема может заключатся в неправильном способе задачи кодировке странице…
…а это было так…. -
Madkin
Активный пользователь- С нами с:
- 23 янв 2008
- Сообщения:
- 18
- Симпатии:
- 0
Доброго времени суток!
Мужики, что я делаю не так?
Ситуевина следующая:
1. База, таблица, записи в кодировке cp1251
2. Страница в кодировке cp1251
3. На странице даже вставлен mysql_query(«SET NAMES ‘cp1251′»);В итоге страница вылезает в кодировке cp1251(как и задумывалось), данные из мускуля на странице отображаются знаками вопроса(что нежелательно). (((
-
- С нами с:
- 8 апр 2007
- Сообщения:
- 5.433
- Симпатии:
- 0
Может сервер высылает заголовок http в другой кодировке?
Попробуйте header(«Content-type: text/html; charset=windows-1251»); -
Madkin
Активный пользователь- С нами с:
- 23 янв 2008
- Сообщения:
- 18
- Симпатии:
- 0
Ну я так понимаю, что изменив в апаче AddDefaultCharset UTF-8 на CP-1251, я вроде бы как сделал тоже самое.
К сожалению проблема осталась (((.
Есть ли смысл дефолтовой кодировкой мускуля сделать CP-1251? Сейчас в мускуле повсюду юникод — созданное мной как белая ворона в виндовой кодировке лежит.
-
Madkin
Активный пользователь- С нами с:
- 23 янв 2008
- Сообщения:
- 18
- Симпатии:
- 0
Еще раз, здравствуйте!
Продолжаю мучение:
Выставил дефолтовую кодировку для mysql в cp1251 — результат от же ((((
Может кто-нить подбросит совет? вот что имею:
1. Апаче раздает страницы с параметром AddDefaultCharset CP-1251
2. Мускуль в настройках my.cnf раздел [mysqld] (может тут беда?) имеет 2 параметра
— collation_server = cp1251_general_ci
— character_set_server = cp1251
3. База, таблицы в базе, записи в таблицах в в cp12-51_general_ci
4. Страница в windows-1251
5. Страница имеет mysql_query(«SET NAMES ‘cp1251′»);Со всем этим у меня трабла — все что вытягивается из мускуля — на странице превращается в знаки вопроса.
УПД.
Загугли решают )) Правильно поставленный поисковый вопрос — 80% сделано
Добавил следующее после коннекта с базой — заработало-
mysql_query («set collation_connection=’cp1251_general_ci'»);
Спамибо ответившим.
-
ZMANZ
Активный пользователь- С нами с:
- 10 мар 2008
- Сообщения:
- 161
- Симпатии:
- 0
Здраствуйте!!!
При добавлении информации через блок администратора в базу данных mysql, в базе данных информация отображается иероглифами, но только когда печатаешь русскими буквами!!! При отправке формы английскими или цифрами приходит все нормально!!! Страница с которой происходит отправка имеет кодировку utf8!!! phpMyAdmin 2.6.1, MySQL 4.1.16, Appach 1.3.33 Php 5.1.2!!!
Где и что нужно поменять, чтоб небыло этих иероглифов??? Как я понял идет именно несовместимость кодировок страница в utf8, а mysql 1251!!! А так все отображаеца нормально, проблема именно при поступлении данных в базу, приходят ИЕРОГЛИФЫ!!! -
- С нами с:
- 2 фев 2007
- Сообщения:
- 4.680
- Симпатии:
- 1
- Адрес:
- Минск
привычку не читать первое же сообщение в теме.
Страница 1 из 3
Попросили тут перенести сайт на другой хостинг, а он, как оказалось, до сих пор жил в кодировке cp1251. Вроде ничего страшного — работает, но уж больно по колхозному это в наше время и давно пора перейти на UTF-8.
Перед любыми действиями с базой данных ОБЯЗАТЕЛЬНО СОЗДАЕМ РЕЗЕРВНУЮ КОПИЮ!
Самый быстрый и простой способ — пересохранить копию базу данных в любом текстовом редакторе (sublime text, notepad++) в нужной кодировке и импортировать на место старой. Можно проделать данную операцию используя SQL-запросы в phpMyAdmin.
ALTER DATABASE имя_вашей_базы_данных charset=utf8;
Данный запрос конвертирует базу в указанную кодировку. Кроме этого потребуется конвертировать и сами таблицы. Запрос для конвертации таблицы базы данных:
ALTER TABLE `db_name`.`table_name` CONVERT TO CHARACTER SET utf8 COLLATE utf8_general_ci;
Конвертировать каждую из таблиц по отдельности подобным образом то ещё удовольствие, особенно при большом количестве. Однако можно не мучить себя подобным занятием, а создать последовательность команд посредством одного запроса:
SELECT CONCAT( 'ALTER TABLE `', t.`TABLE_SCHEMA` , '`.`', t.`TABLE_NAME` , '` CONVERT TO CHARACTER SET utf8 COLLATE utf8_general_ci;' ) AS sqlcode FROM `information_schema`.`TABLES` t WHERE 1 AND t.`TABLE_SCHEMA` = 'My_DB_for_convert' ORDER BY 1 LIMIT 0 , 90
Остается только скопировать результаты и вставить их в форму нового SQL запроса.
Подписывайтесь на канал
Яндекс.Дзен
и узнавайте первыми о новых материалах, опубликованных на сайте.
ВАРИАНТ 15
Задание 1.
Создать форму Электронная анкета (см. рис. ниже).
Поле № 1 – текстовое поле, первая буква содержимого поля должна быть всегда строчной.
Поле № 2 – текстовое поле типа дата.
Поля № 3 – поле вида поле вида «список». В списке должны быть указаны следующие категории: Рабочий, Служащий, Интеллигенция.
Поле № 4 – поля вида «флажок»
Поля № 5 – текстовые поля типа «число». Содержимое полей может быть только целым числом.
Поле № 6 – поле, в котором должен быть выполнен расчет общих затрат.
Задание 2.
Растиражировать созданную форму (10 анкет) и провести тестирование. После заполнения каждую копию формы сохранить как запись базы данных в кодировке Windows.
Задание 3.
Создать базу данных, в которую импортировать полученные в результате анкетирования данные (поле Итого не импортировать).
В полученной таблице добавить левое крайнее поле для номера по порядку. Это поле сделать ключевым.
Задание 4.
Создать запрос для расчета суммарных затрат (ИТОГО).
Создать запрос для расчета возраста в годах.
Задание 5.
Произвести экспорт запроса по расчету возраста в текстовый процессор Word. Средствами Word создать диаграмму по возрасту анкетируемых.
| Тема: | Выполнить задания (Вариант 15). Задание 1. Создать форму Электронная анкета. Задание 2. Растиражировать созданную форму (10 анкет) и провести тестирование. После заполнения каждую копию формы сохранить как запись базы данных в кодировке Windows и тд |
| Артикул: | 1206318 |
| Дата написания: | 20.05.2022 |
| Тип работы: | Контрольная работа |
| Предмет: | Информационные технологии управления персоналом |
| Количество страниц: | 18 |

Всем доброго вечера
Нужна ваша помощь с лабораторной работой
«В текстовом процессоре Word создать форму в виде электронной анкеты (в соответствие со своим вариантом) и защитить ее с помощью пиктограммы на панели инструментов Формы БЕЗ ПАРОЛЯ. Файлу должно быть присвоено имя, состоящее из:
— символов Анк;
— фамилии разработчика.
Например, Анк Иванов или Анк Сидоров или Анк Петров
Растиражировать созданную форму в соответствие со своим вариантом и провести тестирование. После заполнения каждую копию формы сохранить как запись базы данных в кодировке Windows.
«Склеить» полученные текстовые файлы с результатами тестирования в один результирующий и присвоить ему имя, состоящее из:
— символов Рез;
— фамилии разработчика;
— расширения txt.
Например, Рез Иванов.txt или Рез Сидоров.txt или Рез Петров.txt
Импортировать этот файл в табличный процессор или СУБД в соответствии со своим вариантом и выполнить предусмотренную заданием обработку этих данных. Полученной Книге или Базе данных присвоить имя, состоящее из:
— слова Данные;
— фамилии разработчика.
Например, Данные Иванов или Данные Сидоров или Данные Петров
Отчет должен быть оформлен в виде подкаталога (папки), в котором должны быть файлы:
— исходная форма
— результирующий текстовый файл с данными анкетирования (или 10 файлов по каждой анкете)
— Книга Excel или База данных (в соответствие с заданием)
— текстовый файл с импортированной таблицей и созданной диаграммой (Задание 5) и с кратким описанием порядка проведенной работы»
Я прикрепил задания ниже.
Суть в том, что я никогда не делал ничего подобного
Два дня потратил, ничего не вышло
Я понимаю что просить сделать все это нагло
Подскажите пожалуйста как создать эту форму в виде анкеты
Вернуться к обсуждению:
Создание формы в ms Wors MS Word
__________________
Помощь в написании контрольных, курсовых и дипломных работ, диссертаций здесь
Бывает необходимо проектировать базы данных, записи которой содержат специальные символы, не входящие в какой-либо из алфавитов. Поэтому возникает надобность в использовании кодировки Юникод (UTF). О том как подружить MSSQL и UTF будет рассказано в данной статье.
Допустим требуется спроектировать базу данных (БД) для MSSQL содержащую англо-русский словарь. Соответственно поля этой таблицы будут следующими:
- Английское слово
- Транскрипция
- Перевод
Международный фонетический алфавит (International Phonetic Alphabet — IPA) из которого составляется транскрипция содержит специальные символы которые не в ходят ни английский алфавит, ни в русский (само собой), ни в какой-либо другой, например: ə, ð, æ, ʃ, ʌ и так далее.
В Microsoft SQL Server (MSSQL) присутствуют только национальные кодировки, то есть таблицы символов для конкретного языка. Если выполнить запрос:
|
SELECT * FROM ::fn_helpcollations() |
То можно увидеть список всех доступных кодировок. Список огромный (у меня 3885 строк).
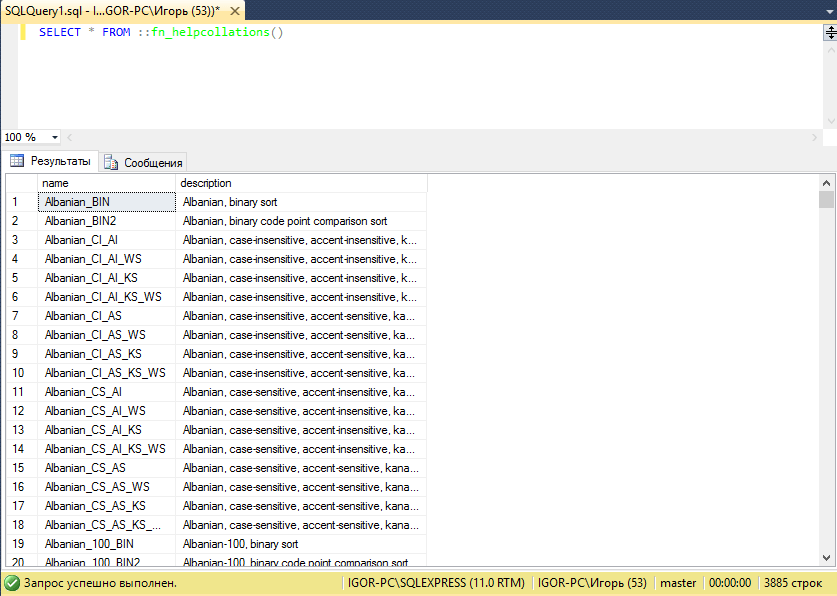
Все эти кодировки применимы в MSSQL к полям с однобайтовыми типами данных: char, varchar и text.
Чтобы установить нужную кодировку (например Latin1_General_CI_AI), необходимо воспользоваться оператором COLLATE:
|
create table dictionary ( id int not null, word varchar(30) COLLATE Latin1_General_CI_AI null, transcription varchar(40) null, translation text null, constraint PK_DICTIONARY primary key nonclustered (id) ) go |
В списке кодировок MSSQL отсутствует UTF (Юникод). Так как же настроить ее использование?
В MSSQL реализованы двухбайтовые типы данных: nchar, nvarchar и ntext. Как раз они и поддерживают использование всех символов кодировки UTF.
Использование типов данных nchar, nvarchar и ntext имеет серьезную особенность. Чтобы данные, заносимые в БД, корректно обрабатывались, нужно перед вставляемым значением дописать букву N — это сигнал для SQL сервера, что вводимые данные это Юникод.
|
INSERT INTO tableName VALUES (N‘Значение’) |
Рассмотрим пример. Создадим таблицу, где поле transcription имеет тип nvarchar:
|
create table dictionary ( id int not null, word varchar(30) null, transcription nvarchar(40) null, translation text null, constraint PK_DICTIONARY primary key nonclustered (id) ) go |
Добавление записи в таблицу будет происходить так:
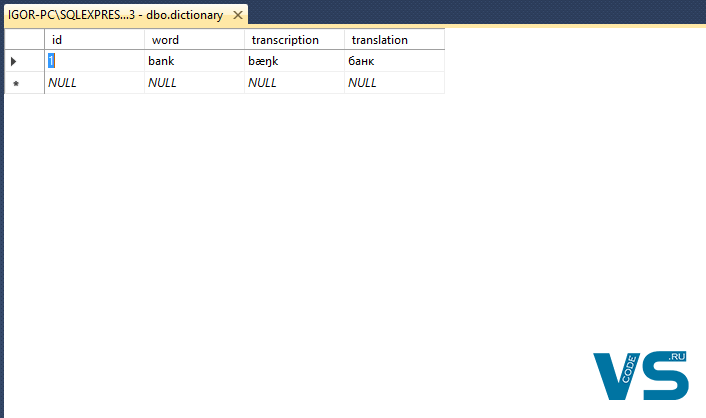
|
INSERT INTO dictionary VALUES (1, ‘bank’, N‘bæŋk’, ‘банк’) |
Видим, что данные корректно отображаются:
Спасибо за прочтение статьи о MSSQL и UTF!
-
Доступные статьи
-
MySQL
-
Кодировки в MySQL
Работа с кодировками в MySQL 4.1.11 и выше
- Тестовая машина
- Устанавливаем MySQL
- Начало работы
- Разумные выводы
- Настройка кодировок
- Через names
- Через системные переменные
- Через настройки сервера
- Что делать, если данные внесены в неправильной кодировке
- Правильный вариант работы с MySQL
Полезность первоисточника информации трудно переоценить, поэтому не поленитесь и скачайте полный мануал от разработчиков MySQL — http://dev.mysql.com/doc/
Тестовая машина
test# uname -a FreeBSD test.dm 7.0-RELEASE FreeBSD 7.0-RELEASE #1: Fri May 9 15:40:21 YEKST 2008 zg@test.dm:/usr/obj/usr/src/sys/GATE i386 test#
Устанавливаем MySQL 5.1
test# pkg_add -r mysql51-server Fetching ftp://ftp.freebsd.org/pub/FreeBSD/ports/i386/ packages-7.0-release/Latest/mysql51-server.tbz... Done. Fetching ftp://ftp.freebsd.org/pub/FreeBSD/ports/i386/ packages-7.0-release/All/mysql-client-5.1.22.tbz... Done. Added group "mysql". Added user "mysql". ************************************************************************ Remember to run mysql_upgrade (with the optional --datadir=<dbdir> flag) the first time you start the MySQL server after an upgrade from an earlier version. ************************************************************************ test# echo mysql_enable="YES" >> /etc/rc.conf test# cp /usr/local/share/mysql/my-large.cnf /etc/my.cnf test# /usr/local/etc/rc.d/mysql-server start Starting mysql. test# sockstat | grep mysql mysql mysqld 1154 13 tcp4 *:3306 *:* mysql mysqld 1154 14 stream /tmp/mysql.sock test#
Пускай это не самый «правильный» способ установки MySQL-сервера, зато быстрый и рабочий.
Начало работы
Итак, sockstat показала, что сервер работает, а установка говорит о том, что сервер абсолютно девственный. Чем это грозит? Кодировки по умолчанию выставлены англоязычные, а значит, будут проблемы при использовании кирилицы. Но как это распознать? Проверяем:
test# mysql Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 2 Server version: 5.1.22-rc-log FreeBSD port: mysql-server-5.1.22 Type 'help;' or 'h' for help. Type 'c' to clear the buffer. mysql> use test; Database changed mysql> create table `test` (`field` VARCHAR(60)); Query OK, 0 rows affected (0.01 sec) mysql> insert into `test` values ('иван'), ('родил'), ('девчёнку'); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql>
Первым делом используем тестовую базу, которая уже есть на сервере, затем создаём в ней таблицу и вставляем в неё три слова на русском, про кодировки мы пока ничего не знаем и знать не хотим ))).
Пока всё хорошо и радужно, никаких ошибок нет, пробуем сделать выборку:
mysql> select * from `test`; +----------+ | field | +----------+ | иван | | родил | | девчёнку | +----------+ 3 rows in set (0.01 sec) mysql> select * from `test` where `field` like "иван"; +-------+ | field | +-------+ | иван | +-------+ 1 row in set (0.00 sec)
Как видно, запросы работают абсолютно корректно, так где же грабли?… Оказывается мы на них уже стоим:
mysql> select * from `test` order by `field` DESC; +----------+ | field | +----------+ | девчёнку | | родил | | иван | +----------+ 3 rows in set (0.01 sec)
Запрос на выборку с обратной сортировкой привёл к тому, что записи просто вывелись в обратном порядке, но не по алфавиту… До удара граблей остаются считанные секунды, но пока растянем удовольствие  Сперва ответим на вопрос — почему поля не сортируются по алфавиту? У MySQL имеется мощный и богатый механизм для работы с интернациональными наборами символов, но.. но откуда MySQL узнает, что наши символы — есть русский алфавит, мы же качали английскую версию? Ничего не остаётся, как идти ковырять мануал на предмет кодировок…
Сперва ответим на вопрос — почему поля не сортируются по алфавиту? У MySQL имеется мощный и богатый механизм для работы с интернациональными наборами символов, но.. но откуда MySQL узнает, что наши символы — есть русский алфавит, мы же качали английскую версию? Ничего не остаётся, как идти ковырять мануал на предмет кодировок…
После того, как загрузился 16-метровый мануал, можно не полениться и прочитать первые пару-тройку страниц с оглавлением )), а можно просто сделать поиск на предмет charset или character set. Не суть важно, но через некоторое время можно найти раздел 9.1.2. Character Sets and Collations in MySQL, в котором написано много и интересно, а, главное, содержательно про то, каким образом можно и нужно работать с кодировками.
Расставляя точки над и, Character Set — транслируется как «кодировка», а Collation — сравнение. В чём разница? Сравнение — это правила сравнения букв кодировки. Сравнения работают только в рамках кодировки, и нельзя сравнивать данные в латинице по правилам кирилицы. Поясню на примере: мы, как увидим позже, внесли данные в таблицу на латинице, а сортировать нужно на кирилице, для чего можно использовать ключевое слово collate:
mysql> select * from `test` order by `field` collate cp1251_general_ci DESC; ERROR 1253 (42000): COLLATION 'cp1251_general_ci' is not valid for CHARACTER SET 'latin1' mysql>
MySQL отказывается это делать… но почему? Потому, что latin1 не поддерживает сравнение в кирилице, а доступные «сравнения» можно увидеть так:
mysql> show collation like 'latin1%'; +-------------------+---------+----+---------+----------+---------+ | Collation | Charset | Id | Default | Compiled | Sortlen | +-------------------+---------+----+---------+----------+---------+ | latin1_german1_ci | latin1 | 5 | | Yes | 1 | | latin1_swedish_ci | latin1 | 8 | Yes | Yes | 1 | | latin1_danish_ci | latin1 | 15 | | Yes | 1 | | latin1_german2_ci | latin1 | 31 | | Yes | 2 | | latin1_bin | latin1 | 47 | | Yes | 1 | | latin1_general_ci | latin1 | 48 | | Yes | 1 | | latin1_general_cs | latin1 | 49 | | Yes | 1 | | latin1_spanish_ci | latin1 | 94 | | Yes | 1 | +-------------------+---------+----+---------+----------+---------+ 8 rows in set (0.00 sec) mysql>
Ни о какой кирилице не может идти и речи… Куда копать?.. В создание таблицы!
mysql> show create table `test`; +-------+-------------------------------------------------+ | Table | Create Table | +-------+-------------------------------------------------+ | test | CREATE TABLE `test` ( `field` varchar(60) DEFAULT NULL ) ENGINE=MyISAM DEFAULT CHARSET=latin1 | +-------+-------------------------------------------------+ 1 row in set (0.00 sec)
Ага! По-умолчанию при создании таблицы была взята кодировка latin1, значит, если мы изменим таблицу и укажем ей, что надо использовать кирилистическую кодировку, то всё заработает?… В мануале написан пример про изменение кодировки таблицы, используем его:
mysql> alter table `test` charset "cp1251"; Query OK, 3 rows affected (0.02 sec) Records: 3 Duplicates: 0 Warnings: 0
Ок! Проверяем, что получилось…
mysql> select * from `test` order by `field` collate cp1251_general_ci DESC; ERROR 1253 (42000): COLLATION 'cp1251_general_ci' is not valid for CHARACTER SET 'latin1'
Хм.. опять та же ошибка, но откуда ей взяться?!..
mysql> show create table `test`; +-------+-------------------------------------------------+ | Table | Create Table | +-------+-------------------------------------------------+ | test | CREATE TABLE `test` ( `field` varchar(60) CHARACTER SET latin1 DEFAULT NULL ) ENGINE=MyISAM DEFAULT CHARSET=cp1251 | +-------+-------------------------------------------------+ 1 row in set (0.00 sec)
Ого, структура таблицы резко изменилась, теперь у неё задана одна кодировка, а у поля совсем другая.. :(( Порыв ещё мануал, можно изменить и кодировку столбца:
mysql> alter table `test` modify `field` varchar(60) charset "cp1251"; Query OK, 3 rows affected, 3 warnings (0.02 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> show create table `test`; +-------+------------------------------------------+ | Table | Create Table | +-------+------------------------------------------+ | test | CREATE TABLE `test` ( `field` varchar(60) DEFAULT NULL ) ENGINE=MyISAM DEFAULT CHARSET=cp1251 | +-------+------------------------------------------+ 1 row in set (0.01 sec)
Ну вот!!! Злой кодировки latin1 нет и в помине, можно проверять наш роддом )))
mysql> select * from `test` order by `field` collate cp1251_general_ci DESC; +----------+ | field | +----------+ | ???????? | | ????? | | ???? | +----------+ 3 rows in set (0.00 sec)
И вот тот страшный удар граблями, который так долго оттягивался! Внимательный читатель мог заметить, что когда была сделана попытка принудительно сменить кодировку столбца, содержащего данные в latin1, то на каждую запись, содержащую русские буквы, у MySQL был варнинг! Это был крик о том, что сервер не знает, каким образом можно перевести данные из latin1 в cp1251, ну и лучшего способа, чем заменить символы не latin1 вопросиками, он не нашёл :))). Роддом безвозвратно потерян потому, что теперь вместо кирилицы в базе содержатся вопросики..
Вопросиков можно было избежать
На самом деле, ситуация, когда изначально выставлена неправильная кодировка, встречается сплошь и рядом. Симптомы можно выявить следующим образом:
mysql> show variables like "char%"; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | latin1 | | character_set_connection | latin1 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | latin1 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/local/share/mysql/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.02 sec)
Именно эти переменные отвечают за дефолтные значения кодировок.
character_set_client— кодировка, в которой данные будут поступать от клиентаcharacter_set_connection— кодировка по умолчанию для всего, что в рамках соединения не имеет кодировкиcharacter_set_database— кодировка по умолчанию для базcharacter_set_filesystem— кодировка для работы с файловой системой (LOAD DATA INFILE, SELECT … INTO OUTFILE, и т.д.)character_set_results— кодировка, в которой будет выбран результатcharacter_set_server— кодировка, в которой работает серверcharacter_set_system— кодировка, в которой задаются идентификаторы MySQL, всегда UTF8character_sets_dir— папка с кодировками
ВАЖНО: Если character_sets_dir установлена неверно, то работа с кодировками будет под угрозой. Не пытайтесь менять её значение, если вы неуверены в своих силах. Если вы системный администратор, то перед установкой лучше ознакомиться с мануалом.
Наиболее значимые для простых пользователей следующие переменные: character_set_client, character_set_results, character_set_connection. Поскольку именно они отвечают за внесение, извлечение информации и создание таблиц/баз соответственно. Какими они могут быть?
mysql> SHOW CHARACTER SET; +----------+-----------------------------+---------------------+--------+ | Charset | Description | Default collation | Maxlen | +----------+-----------------------------+---------------------+--------+ | dec8 | DEC West European | dec8_swedish_ci | 1 | | cp850 | DOS West European | cp850_general_ci | 1 | | hp8 | HP West European | hp8_english_ci | 1 | | koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 | | latin1 | cp1252 West European | latin1_swedish_ci | 1 | | latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 | | swe7 | 7bit Swedish | swe7_swedish_ci | 1 | | ascii | US ASCII | ascii_general_ci | 1 | | hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 | | koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 | | greek | ISO 8859-7 Greek | greek_general_ci | 1 | | cp1250 | Windows Central European | cp1250_general_ci | 1 | | latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 | | armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 | | utf8 | UTF-8 Unicode | utf8_general_ci | 3 | | cp866 | DOS Russian | cp866_general_ci | 1 | | keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 | | macce | Mac Central European | macce_general_ci | 1 | | macroman | Mac West European | macroman_general_ci | 1 | | cp852 | DOS Central European | cp852_general_ci | 1 | | latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 | | cp1251 | Windows Cyrillic | cp1251_general_ci | 1 | | cp1256 | Windows Arabic | cp1256_general_ci | 1 | | cp1257 | Windows Baltic | cp1257_general_ci | 1 | | binary | Binary pseudo charset | binary | 1 | | geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 | +----------+-----------------------------+---------------------+--------+ 26 rows in set (0.00 sec)
Любую из этих кодировок можно пользовать на свой вкус. Обычно русскоязычные пользователи предпочитают cp1251 или utf8, но по сути, неважно, в какой кодировке хранятся данные, важно, чтобы она была изначально правильно указана и данные были корректно внесены.
Настройка кодировок
Мануал предлагает нам три варианта задания кодировок:
- Через names
- Через непосредственно переменные character_set_*
- Через настройки самого сервера
ВНИМАНИЕ!!! Первые два варианта работают только в рамках текущего соединения. Это значит, что при следующем подключении все настройки вернутся в начальное состояние! Чтобы не выставлять кодировку каждый раз, нужно воспользоваться третьим вариантом.
Вариант 1 — Через names
mysql> set names 'cp1251'; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | cp1251 | | character_set_connection | cp1251 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | cp1251 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/local/share/mysql/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.02 sec)
Ну, тут всё ясно, три самые нужные кодировки в одном )))
Вариант 2 — Через непосредственно переменные character_set_*
mysql> set @@character_set_client='cp1251'; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | cp1251 | | character_set_connection | latin1 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | latin1 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/local/share/mysql/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.01 sec)
Более детальная настройка, чем names.
Вариант 3 — Через настройки самого сервера
Тут можно пойти двумя путями — либо через конфиг файл:
---- Файл my.cnf [client] # Для местного клиента default-character-set=cp1251 .... [mysqld] # Для всего сервера default-character-set=cp1251 ....
либо
shell> mysqld --character-set-server=cp1251
Ещё можно при конфигурировании задать кодировку по умолчанию
shell> ./configure --with-charset=latin1
Но лучше, когда кодировка настраивается прямо в соединении.
Что делать, если данные внесены в неправильной кодировке
Если база/таблица/данные были созданы/внесены в кодировке отличной от нужной, то необходимо сделать следующее:
- Создать бэкап базы данных
- Создать текстовый дамп базы в SQL-запросах (mysqldump или PhpMyAdmin)
- С помощью текстового редактора исправить вхождения неверной кодировки на нужную (а лучше попросту удалить всю информацию о кодировках и сравнениях)
- Удалить базу/таблицу
- Выставить нужную кодирвку на клиента/соединение
- Импортировать данные исправленного SQL-дампа
Этот вариант подходит почти для всех случаев, за исключением некоторых особых ситуаций, например, когда сравнение, выставленное по-умолчанию, не уместно для некоторых полей. Пример — поле для хранения пароля, необходимо сравнивать его с учётом регистра, тогда как по-умолчанию выставляется сравнение без учёта регистра.
mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | latin1 | | character_set_connection | latin1 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | latin1 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/local/share/mysql/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.02 sec) ## Кодировки выставлены неверно, нужно их настроить mysql> set names 'koi8r'; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | koi8r | | character_set_connection | koi8r | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | koi8r | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/local/share/mysql/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.02 sec) ## Я работаю через koi8r, поэтому и выставляю её, ## но данные в таблице буду хранить в cp1251 mysql> create table `test2` (`field` varchar(60)) charset cp1251; Query OK, 0 rows affected (0.01 sec) ## Проверяем, всё ли в порядке mysql> show create table `test2`; +-------+--------------------------------------------+ | Table | Create Table | +-------+--------------------------------------------+ | test2 | CREATE TABLE `test2` ( `field` varchar(60) DEFAULT NULL ) ENGINE=MyISAM DEFAULT CHARSET=cp1251 +-------+--------------------------------------------+ 1 row in set (0.01 sec) ## Вносим данные mysql> insert into `test2` values ('и раз'), ('Два'),('три'), ('И ять'), ('шесть'); Query OK, 5 rows affected (0.01 sec) Records: 5 Duplicates: 0 Warnings: 0 ## Проверяем сортировки ## В обычном сравнении "И" и "и" одинаковы, поэтому ## сравнение идёт до первого отличного символа mysql> select * from `test2` order by `field` collate cp1251_general_ci ASC; +-------+ | field | +-------+ | Два | | и раз | | И ять | | три | | шесть | +-------+ 5 rows in set (0.01 sec) ## В бинарном сравнении "И" меньше чем "и", поскольку у неё код меньше mysql> select * from `test2` order by `field` collate cp1251_bin ASC; +-------+ | field | +-------+ | Два | | И ять | | и раз | | три | | шесть | +-------+ 5 rows in set (0.00 sec)
Таким образом, клиент работает в KOI8-R, но данные хранятся в cp1251, MySQL знает об этом и делает перекодировку на лету.
Ну и на посошок:
mysql> set character_set_results='cp1251'; Query OK, 0 rows affected (0.00 sec) mysql> select * from `test2`; +-------+ | field | +-------+ | Х ПЮГ | | дБЮ | | РПХ | | х ЪРЭ | | ЬЕЯРЭ | +-------+ 5 rows in set (0.00 sec)
Выбирать данные можно в любой кодировке, так же, как и вносить, главное — правильно сообщить об этом MySQL.